À quelques détails près, une préposition complexe ?
Ludo Melis
Les prépositions complexes sont généralement considérées comme des séquences plus ou moins fixes qui fonctionnent comme des équivalents des prépositions dites simples, comme le signale l’annonce du colloque.
À … près constitue, dans l’ensemble des éventuelles prépositions complexes, un cas en marge, ne fût-ce que par sa structure bipartite. Cette contribution propose, en premier lieu, une description détaillée des emplois de la séquence, qui n’a guère retenu l’attention des grammairiens et linguistes, (voir toutefois Damourette et Pichon § 3020). Celle-ci servira d’observatoire pour soulever un certain nombre de questions plus générales relatives aux prépositions complexes, aux rapports entre celles-ci et les prépositions simples, mais aussi aux relations entre les prépositions et d’autres ‘classes’ de mots, en particulier les adverbes.
La séquence encadre, dans la plupart des cas, soit un groupe nominal à quantificateur (à quelques / trois N près) soit une groupe nominal précédé d’un démonstratif (à ce N près) ; dans ce dernier cas, le démonstratif peut-être anaphorique ou cataphorique et l’ensemble est alors suivi d’une structure en que (à cette différence près que X était absent lors de la réunion). Les deux ensembles comportent des locutions figées : à peu près d’une part et à cela /ça près de l’autre. Une description plus détaillée permettra de nuancer le tableau et de préciser les rapports que les deux composantes entretiennent avec d’autres usages de à et de près, ainsi que de cerner les rapports syntaxiques internes que celles-ci entretiennent entre autres grâce à une comparaison avec d’autres emplois de à corrélé à une préposition, par exemple à trois mètres (de distance) de… , ainsi qu’avec ceux de près / près de. L’analyse permettra de discuter la suggestion de Damourette et Pichon que près est la tête de la structure et que le syntagme introduit par à en constitue le complément, suggestion qui attribue à l’ensemble des propriétés syntaxiques peu communes en français. Les propriétés syntaxiques externes et les propriétés sémantiques associées requièrent également une analyse détaillée : l’ensemble peut en effet fonctionner entre autres
comme adjoint du verbe
Elle se réjouirait de retrouver, à quelques décimales près, son score des élections législatives de 1997 (35,6 % des suffrages exprimés, contre 36,3 % il y a un an). (Le Monde)
comme adjoint exceptif lié tant au verbe qu’à un groupe nominal :
- puisque les communes non-desservies par GDF ne peuvent l’être, à quelques exceptions près, par aucun autre opérateur privé (Id.)
comme adjoint à un groupe nominal :
- A cent près, ils sont redescendus dans les puits. (cité Damourette et Pichon § 3020)
ou remplir un rôle plus central comme dans :
- On n’en est plus à une mélancolie près. (Le Monde).
Le rapprochement avec sauf et excepté que les sources lexicographiques suggèrent demande à être scruté dans ce contexte.
La structure à … près représente un cas peu fréquent, voire peut-être singulier en français ; de ce fait la confrontation avec des données provenant d’autres langues, comme le néerlandais op … na (litt. sur … après ) qui possède des propriétés analogues peut être éclairante.
La description permet de soulever un certain nombre de questions intéressant l’ensemble des prépositions, simples et complexes.
- Faut-il admettre qu’il existe en français, outre des prépositions et quelques postpositions, des ‘circumpositions’, dont à … près , type syntaxique qui ne peut être réalisé que par une préposition complexe ? En cas de réponse positive, la notion d’équivalence distributionnelle entre les prépositions complexes et les prépositions simples est à nuancer.
- Quel est l’impact des rapports syntaxiques entre les composantes de à … près sur la typologie des prépositions complexes ?
- Dans quel sens peut-on maintenir que les prépositions complexes sont des équivalents distributionnels des prépositions simples quant aux propriétés syntaxiques externes et sur le plan sémantique ? Faut-il définir une telle équivalence entre unités lexicales, simples ou complexes, ou entre classes de mots ou de constructions ?
- L’examen de près comme composante de la préposition complexe mène-t-il à revoir la problématique des relations entre prépositions et adverbes ?
L’étude d’une configuration singulière pourra ainsi alimenter les débats sur les prépositions complexes en français.
La polysémie réduite des prépositions complexes
Walter De Mulder
Il a déjà été signalé par plusieurs auteurs que la polysémie des prépositions complexes s’avère plus restreinte que celle des prépositions simples (Fagard 2009 : 106, Stosic & Fagard 2019 : 12). Pour expliquer cette observation, Stosic & Fagard (2019 : 12) renvoient au fait que les prépositions complexes comportent un élément lexical : celui-ci entraînerait une spécification sémantique plus grande, comme l’a déjà signalé Borillo (2002 : 144). Dans cette communication, nous nous proposons de décrire la structure polysémique des prépositions complexes et de vérifier l’hypothèse avancée ci-dessus. Nous nous limiterons toutefois, à quelques exceptions près, aux prépositions complexes considérées comme prototypiques par Stosic & Fagard (2019). Celles-ci comportent un élément lexical et distribuent sur les formes dont elles sont composées les trois fonctions que les prépositions simples réunissent en une seule forme : dans au sommet de, par exemple, la préposition initiale à rattache l’ensemble de la préposition complexe à l’élément recteur, la préposition simple finale de lie le complément, et l’élément central, qui est de nature lexicale, apporte une précision sémantique sur la relation entre les deux éléments reliés par la préposition (Stosic & Fagard 2019 : 12).
Nous étudierons la polysémie de ces prépositions complexes à partir de l’idée selon laquelle les différents sens des prépositions forment un réseau sémantique, idée dont on s’est servi en sémantique cognitive pour décrire, entre autres, le sens de la préposition anglaise over (pour un aperçu, voir Breda 2014, Pawelec 2009 : 82-105), et qui a été développée davantage par Taylor (2003, 2014). Il sera ainsi confirmé qu’en comparaison avec les prépositions simples, la polysémie des propositions complexes semble plutôt limitée. Il suffit à ce propos de comparer, par exemple, le nombre de sens différents de sur par rapport à ceux qu’on peut distinguer pour la préposition complexe au-dessus de. Nous présenterons une analyse plus exhaustive du sémantisme de cette préposition complexe lors de notre communication, mais ses emplois les plus fréquents semblent au prime abord exprimer les sens spatiaux suivants :
- une relation verticale entre les entités désignées par les arguments de la préposition :
1) Au-dessus de Smara, le ciel était sans fond, glacé, aux étoiles noyées par la nuée blanche de la lumière lunaire. (Frantext, LE CLÉZIO, Jean-Marie Gustave (1980). Désert, p. 38)
- un mouvement parcourant un trajet « en demi-cercle » passant au-dessus de l’objet désigné par le complément de la préposition :
2) Chaque année, une grande partie de la population a pour tradition de sauter au-dessus de petits feux de joie dans la nuit du mardi au mercredi qui précède l’équinoxe du printemps (ici en 2008, au nord de Téhéran). (AFP, https://www.lefigaro.fr/international/2010/03/17/01003-20100317ARTFIG00481-la-fete-du-feu-ravive-la-fronde-iranienne-.php, consulté le 9/7)
- un sens équivalant plus ou moins à ‘de l’autre côté de’ :
3) Batisti habitait rue des Flots-Bleus, au-dessus du pont de la Fausse-Monnaie, une villa qui surplombait Malmousque, la pointe de terre la plus avancée de la rade. (Frantext, IZZO, Jean-Claude (1995). Total Khéops, p. 331)
- un sens de recouvrement :
4) Une plinthe de recouvrement est mis au-dessus de la plinthe ancienne. (https://www.maestro-panel.com/fr/produits/accessoires/plinthe-de-recouvrement, consulté le 7/9)
La préposition connaît en outre des emplois non spatiaux, dans lesquels elle signale, en gros, une idée de supériorité qui peut s’appliquer à différents domaines, ce qui permet différentes interprétations plus précises :
5) Au hasard d’une patrouille, l’agent de la police de l’autoroute Dean Forsyth prit en chasse une voiture sur la route Montbury-Aurora, après avoir constaté qu’elle avait brûlé un stop et qu’elle roulait au-dessus de la vitesse autorisée. (Frantext, DICKER, Joël (2012). La Vérité sur l’Affaire Harry Quebert, 3. Election Day – TROISIÈME PARTIE Le paradis des écrivains, p. 603).
6) On lui a dit que hormis le Tout-Paris, personne ne savait qu’il était l’auteur du mail. Quand bien même il s’agissait d’un secret de polichinelle que chacun pouvait éventer en trois clics sur Internet, son nom resterait officiellement au-dessus de tout soupçon […] (Frantext, BOUILLIER, Grégoire, Le dossier M. Livre 2, 2018, Niveau 8 – PARTIE XXXII – Livre 2 APRÈS ET BIEN AVANT, p. 632)
7) Oui, l’enfant aux yeux gris était là, et la jeune fille aussi, ils regardaient la mer. Et je les ai ramenés à moi eux aussi comme je le fais de vous, de la mer et du vent et je vous ai enfermés dans cette chambre égarée au-dessus du temps. (Frantext, DURAS, Marguerite (1980). L’Été 80, 8, p. 72)
Dans notre communication, nous présenterons une analyse plus précise de la structure du réseau sémantique associé à la préposition au-dessus de, mais aussi de ceux associés à d’autres prépositions complexes, comme au sommet de ou en face de (en l’opposant à face à). Ceci nous amènera à nous poser les questions suivantes : les prépositions complexes ont-elles un sens de base dont on peut dériver les autres emplois ? Si oui, dispose-t-on de critères pour décider quel est le sens de base ? Suffit-il d’assigner un seul sens de base à la préposition complexe, les autres sens étant alors plutôt conçus comme des emplois dérivés en combinant le sens des prépositions concernées à des éléments du contexte ? Ou faut-il considérer les différentes interprétations des prépositions complexes comme des sens autonomes ?
Pour répondre enfin à notre question initiale, portant sur le degré plutôt limité de la polysémie des prépositions complexes par rapport à celle des prépositions simples, nous nous intéresserons aux rapports entre les différents sens, et notamment aux rapports dits « métaphoriques », qui permettent de passer du sens spatial aux autres sens. Il ressort de nos premières recherches sur corpus sur au-dessus de, mais aussi sur au sommet de par exemple, que les sens métaphoriques que développent ces prépositions résultent de transferts, du domaine spatial à d’autres domaines, d’un sens schématique obtenu par abstraction à partir de leur sens spatial, sens schématique qui correspondrait, pour au-dessus de par exemple, en gros, à l’idée de supériorité qu’on retrouve également dans son sens spatial (voir p.ex. la définition de Vandeloise 1991 : 86-87). Cette observation semble confirmer l’idée de Borillo (2002 : 144) selon laquelle la présence des éléments lexicaux dans les prépositions complexes apporte à celles-ci « une charge sémantique relativement forte et […] les spécialise dans l’expression d’un type de relation qui les rattache plus étroitement au domaine spatial – ou temporel […] ». Cette idée n’est pourtant probablement pas suffisante pour expliquer le degré de polysémie réduit de chaque préposition complexe. Marque-Pucheu (2001) signale ainsi des emplois métaphoriques d’autres prépositions complexes (ou locutions prépositionnelles) comme face à, à l’écart de, etc., qui ne sauraient être expliqués exhaustivement à partir du sens spatial (ou des sens spatiaux) de ces prépositions. Notre objectif final sera de proposer également une explication pour ces cas, à partir de l’idée que l’interprétation des métaphores nécessite le recours à des cadres (frames) de connaissances encyclopédiques.
Bibliographie
Borillo, Andrée (2002). Il y a prépositions et prépositions. Travaux de linguistique 42-43, 141-155.
Brenda, Maria (2014). The Cognitive Perspective on the Polysemy of the English Spatial Preposition Over. Newcastle upon Tyne, Cambridge Scholars Publishing.
De Mulder, Walter (2003). La préposition au-dessus de : un cas de grammaticalisation ? Verbum XXV, 291-305.
Fagard, Benjamin (2009). Prépositions et locutions prépositionnelles : un sémantisme comparable ? Langages 173, 95-113.
Marque-Pucheu, Christiane (2001). Les locutions prépositives : du spatial au non-spatial. Langue française 129, 35-53.
Pawelec, Andrzej (2009). Prepositional Network Models. A Hermeneutical Study. Kraków, Jagiellonian University Press.
Stosic, Dejan & Fagard, Benjamin (2019). Les prépositions complexes en français. Pour une méthode d’identification multicritère. Revue Romane 541, 8-38.
Taylor, John (2003). Cognitive Grammar. Oxford, Oxford University Press.
Taylor, John (2014). The Mental Corpus. How Language is Represented in the Mind. Oxford, Oxford University Press.
Vandeloise, Claude (1992). Spatial Prepositions. A Case Study from French. Chicago et Londres, The University of Chicago Press.
Les prépositions complexes dans les langues romanes : évolution parallèle et contact linguistique
Benjamin Fagard
Du latin aux langues romanes, il y a un mouvement général et bien connu du synthétique (système casuel, morphologie verbale, préfixes verbaux, particules conjonctives) à l’analytique (disparition des cas et développement des prépositions, apparition des auxiliaires temporels, des marqueurs discursifs issus de groupes prépositionnels). Il a été démontré que ce mouvement est panroman, mais présente certaines disparités d’une langue à l’autre (Lamiroy 2011, Böhme-Eckert 2004, Carlier 2007, De Mulder & Lamiroy 2012, Fagard & Mardale 2012).
Un aspect moins étudié de cette évolution est l’émergence des prépositions complexes, un phénomène qui semble relativement uniforme dans la Romania, mais pour lequel on manque d’études diachroniques contrastives qui permettraient de déterminer dans quelle mesure le contact linguistique entre langues romanes – ou même plus largement avec d’autres langues – a pu avoir pour effet d’harmoniser les systèmes linguistiques romans de ce point de vue. Le contact linguistique, entendu au sens large, semble en effet susceptible d’expliquer la formation d’au moins une partie des prépositions complexes, par exemple sous l’égide de (anglais under the aegis of, italien sotto l’egida di, allemand unter der Ägide von, grec moderne ipó tin ejíða + GEN, cf. Bortone 2020 : 251). Cependant, il apparaît également que certaines structures pourraient avoir émergé en parallèle et à peu près à la même période dans différentes langues romanes, par exemple a(u) ch(i)ef de « au bout de » en ancien français, a capo di en italien médiéval et ao cabo de en portugais médiéval (Fagard & De Mulder 2012, Piunno & Ganfi 2017, Lima 2014, 2019ab). L’importance du contact linguistique pourrait d’ailleurs avoir joué bien au-delà des langues romanes (Hüning 2014, Bonnet & Fagard 2020). Pour les langues romanes, on peut donc se demander quelle est la part de l’évolution interne et la part du contact linguistique dans l’émergence des prépositions complexes.
Dans cette présentation, nous prendrons appui sur les corpus diachroniques disponibles pour tenter d’apporter un début de réponse à cette question, en combinant des études quantitatives et l’étude qualitative de quelques séquences.
Bibliographie
Böhme-Eckert, Gabriele. 2004. Le français parmi les langues romanes. Langue française 141, 56-68.
Bonnet, Guillaume & Benjamin Fagard. 2020. Complex Prepositions in Albanian: a first assessment. In Fagard, B., J. Pinto de Lima, E. Smirnova & D. Stosic (eds), Complex Adpositions in European Languages. A Micro-Typological Approach to Complex Nominal Relators. Series: Empirical Approaches to Language Typology [EALT], 65. Berlin & New York : De Gruyter, 265-298.
Bortone, Pietro. 2020. On complex adpositions in Modern Greek. In Fagard, B., J. Pinto de Lima, E. Smirnova & D. Stosic (eds), Complex Adpositions in European Languages. A Micro-Typological Approach to Complex Nominal Relators. Series: Empirical Approaches to Language Typology [EALT], 65. Berlin & New York : De Gruyter, 233-264.
De Mulder, Walter & Lamiroy, Béatrice. 2012. Gradualness of grammaticalization in Romance. The position of French, Spanish and Italian. In K. Davidse, T. Breban, L. Brems & T. Mortelmans (eds) Grammaticalization and Language Change: New reflections. Amsterdam & Philadelphie : John Benjamins, 199-226.
Fagard, Benjamin & Mardale, Alexandru. 2012. The pace of grammaticalization and the evolution of prepositional systems: Data from Romance. Folia Linguistica, 46(2), 303-340.
Fagard, Benjamin & De Mulder, Walter. 2007. La formation des prépositions complexes : grammaticalisation ou lexicalisation ? Langue française 156, 9-29.
Hüning, Matthias. 2014. Over complexe preposities en convergentie. In Freek Van de Velde, Hans Smessaert, Frank Van Eynde & Sara Verbrugge (eds.). Patroon en argument. Een dubbelfeestbundel bij het emeritaat van William Van Belle en Joop van der Horst, 433–445. Louvain : Universitaire Pers Leuven.
Lamiroy, Béatrice. 2011. Degrés de grammaticalisation à travers les langues de même famille. Bulletin de la Societe de Linguistique de Paris 19, 167-192.
Lima, José P. 2014. Grammaticalization of complex prepositions in European Portuguese. In José P. Lima, Studies on Grammaticalization and Lexicalization, 163–183. Munich : Lincom Europa.
Lima, José P. 2019a. On grammaticalized complex prepositions in Portuguese: Deployment, shift, redundancy, complementation. In Benjamin Fagard, José P. Lima & Dejan Stosic (eds.). Les prepositions complexes dans les langues romanes. Special issue of Revue Romane 54(1), Amsterdam & Philadelphie : John Benjamins. 126–140.
Lima, José P. 2019b. Preposições complexas em Português. In Ernestina Carrilho, Ana M. Martins, Sandra Pereira & Joao P. Silvestre (orgs.), Estudos linguísticos e filológicos oferecidos a Ivo Castro, 1181–1211. Lisbonne : Centro de Linguística da Universidade de Lisboa. [https://repositorio.ul.pt/handle/10451/39619]
Piunno, Valentina & Ganfi, Vittorio. 2017. Preposizioni complesse in italiano antico e contemporaneo. Grammaticalizzazione, schematismo e produttivita. Archivio Glottologico Italiano, CII(2). 184–204.
Genre textuel en tant qu’indice de lexicalisation des locutions prépositionnelles
Silvia Adler
Afin de différencier la catégorie de syntagme prépositionnel libre, d’une part, et les catégories de locution prépositionnelle (LP) et de « préposition simple graphiquement composée », partageant toutes les trois le schéma [PREP LE N DE], d’autre part, Adler (2001) avait proposé un test liminaire qui vérifiait la possibilité pour la tête nominale de préserver son sens et sa prédication avec l’argument derrière de dans une séquence non prépositionnelle. Dans l’affirmative, ladite séquence a été reconnue comme une composition analytique, donc un syntagme libre. Dans la négative, la séquence a été dite lexicalisée, synthétique. Autrement dit, l’indice de lexicalisation a été corrélé à l’impossibilité de la préposition simple graphiquement composée ou de la LP d’alterner avec ce même schéma dépouillé de la préposition introductrice [LE N DE]. Du fait de son imprédictibilité sémantique, au fur et à mesure de X a ainsi été classé comme unité lexicale, mais non au commencement de X qui alterne avec le commencement de X et où la relation entre commencement et l’argument X reste intacte dans les deux schémas.
En procédant par l’observation de microsystèmes sémantiques tels les expressions [PREP LE N DE] locatives, temporelles ou notionnelles, Adler (2006, 2007 et 2008) a ensuite développé cette distinction préliminaire entre séquence prépositionnelle libre et séquences lexicalisées, tout en soumettant ces expressions à des tests morphosyntaxiques. Le but était de déterminer le degré de figement desdites séquences. Les tests de la possessivation, du démonstratif ou de la pronominalisation, parmi d’autres, nous ont ainsi permis de distinguer entre « prépositions simples graphiquement composées » (séquences entièrement soudées, non analytiques, et donc formant un seul mot syntaxique) ou des LP[1](séquences figées et lexicalisées vu leur caractère imprédictible, quoiqu’analytiques à certains égards).
Pour ce qui est de la différence entre figement – caractéristique de la LP – ou soudure – caractéristique de la préposition simple graphiquement composée – celle-ci se détermine donc suivant la réaction à divers tests. Les chercheurs qui travaillent dans le domaine de la LP ont reconnu l’efficacité de cette démarche et ont déjà pu identifier divers tests pour décréter le statut soudé ou figé de la séquence prépositionnelle, communément appelée LP. Mentionnons, par exemple, l’opacité ou la transparence sémantique de la séquence (Melis, 2003 : 110) ; la possibilité de modification du noyau nominal par un adjectif intensifiant, comme dans au dam de – au grand dam de (Borillo, 1997 ; Gross, 2006) ; la possibilité de variation au niveau de la préposition introductrice et de la détermination (Gross, 2006). Adler (2006 et 2008) a exploité un test supplémentaire, appliqué à des séquences prépositionnelles spatiales et temporelles, celui de l’anaphorisation nulle. Adler a établi que selon que la séquence [PREP LE N DE] est une « préposition simple graphiquement composée » ou une LP, d’une part, ou une séquence libre, d’autre part, la relation entre l’argument X et ce qui précède n’est pas la même, ce qui influe sur le statut de l’anaphorisation. Dans le cas des prépositions simples graphiquement composées et des LP, là où il est possible d’opérer une anaphorisation par un complément non matérialisé, l’absence du complément correspond à une ellipse, si on s’accorde à reconnaître avec Bally (1950), Zribi-Hertz (1985) ou Adler (2012), que l’ellipse affecte des constituants sémantiquement et structuralement exigés par les constituants restants dans la séquence tronquée, et que l’élément ellipsé est récupérable en contexte. Par contre, dans le cas de la composition syntagmatique prépositionnelle libre, il s’est avéré que la suppression du complément déterminatif en de correspondait à un phénomène d’anaphore associative (Kleiber, 2001).
Récemment, Stosic et Fagard (2019) ont associé les critères morphosyntaxiques et sémantiques fréquemment utilisés dans la définition et la caractérisation des LP à un critère supplémentaire, celui de la fréquence. Leur approche lexicométrique a eu pour objectif de mieux trancher le statut lexicalisé ou non de la séquence prépositionnelle.
Il n’est pas rare que les chercheurs dans le domaine de la LP s’intéressent à une séquence particulière ou à un groupe de séquences partageant un dénominateur commun sémantique ou morphologique. Citons par exemple Stosic (2012), qui enquête sur le statut lexicalisé ou non d’une même séquence prépositionnelle : en passant par. Son étude dévoile que cette séquence fonctionne soit comme
construction libre gérondive à sens transparent, et en rapport avec un prédicat recteur, soit comme préposition complexe en voie de figement, commutable avec via sur un axe paradigmatique. En fait, ce type d’exemple illustrant un statut variable, n’est ni exceptionnel ni rare. Aux environs de pourrait être dit syntagme prépositionnel libre dans aux environs de la gare, du fait d’une alternance possible avec les environs de la gare, mais séquence lexicalisée dans aux environs de 200$, du fait d’une impossibilité d’alternance avec le GN les environs de 200$.
Cette brève illustration aura fait comprendre que bien au-delà de la nécessité de distinguer entre expressions [PREP LE N DE] lexicalisées ou non, et qu’au-delà d’une nécessité résultante de distinguer entre expressions soudées et figées (donc une nécessité de détermination des degrés de lexicalisation) partageant ce même format, un travail supplémentaire de microanalyse s’avère incontournable, puisque le statut d’une même séquence peut varier selon le régime qu’elle introduit, ce qui influe sur son comportement discursif et grammatical. Mais si la même séquence peut avoir un statut lexicalisé ou non selon la nature de son complément, il est légitime de se demander si l’indice de lexicalisation pourrait être corrélé au genre textuel, ou, du moins, si une étude des expressions [PREP LE N DE] dans le contexte de genres textuels variés pourrait non seulement procurer des cas qui méritent notre attention, mais aussi nous aider à répertorier des tendances caractéristiques à chaque genre textuel. Rappelons avec Combettes (1988), Bronckart (1996), Adam (2001), Condamines (2005) et Maingueneau (2005), parmi beaucoup d’autres, que le texte est beaucoup plus qu’une association d’énoncés. Son lectorat et ses enjeux communicatifs, entre autres, privilégieront tel ou tel architecture ou infrastructure stable. Partant ainsi de l’hypothèse que les genres textuels conditionnent certaines productions linguistiques et privilégient certains mécanismes énonciatifs au détriment des autres, les questions qui nous préoccupent dans la présente étude sont donc les suivantes : (a) Un genre textuel particulier serait-il à même de privilégier tel ou tel statut de la même séquence prépositionnelle ? Par exemple, un texte provenant du domaine du tourisme favoriserait-il des emplois prépositionnels typiquement locatifs, à l’encontre d’un texte scientifique ou littéraire, lesquels encourageraient des emplois moins prototypiques de la même séquence ? (b) Dans l’affirmative, quel type de renseignement pourrons-nous dégager concernant le statut de ces séquences ? Même si le résultat attendu risque de paraître relativement banal, puisqu’une corrélation entre genre textuel et degré de lexicalisation semble très logique ou probable – en fonction du type de locution, un travail pareil ne porterait pas qu’un intérêt confirmateur : il aurait un intérêt révélateur et même explicatif, relatif non seulement à la lexicalisation, mais aussi aux caractéristiques des genres textuels et à certaines tendances concernant leurs modes d’expression actuelle. Pour revenir, par exemple, au cas du genre touristique, il se pourrait que celui-ci inclue des tournures poétiques ou figurées, dans un but d’influer sur le rendement stylistique du texte, et par conséquent sur son pouvoir séducteur ou argumentatif.
Quoiqu’il en soit, une réponse à ces questions nécessite une enquête sur corpus, et une analyse introspective de données réelles et attestées, relatives à des textes de types divers. Aussi, l’approche mise en œuvre dans la présente étude consiste-t-elle en une analyse comparée d’un nombre restreint – un échantillon – de séquences prépositionnelles spatiales et temporelles de type [PREP LE N DE] dans un corpus composé de textes appartenant à des genres textuels différents, afin de mettre au jour des fonctionnements propres à ces séquences dans les divers textes, et de dégager des corrélats entre statut de la séquence et genre textuel. Dans la mesure d’une confirmation exploratoire de la présente hypothèse de travail, il sera possible de procéder ultérieurement à une étude plus ample, mais aussi à une étude par microsystèmes (LP de lieu, de temps, notionnelles – but, cause, etc.). Le logiciel ScienQuest qui permet de consulter des textes de plusieurs catégories – encyclopédie, littérature, presse, science et tourisme – nous aidera dans notre enquête.
Références bibliographiques
Adam, J.-M. (2001). « Types de textes ou genres de discours ? Comment classer les textes qui disent de et comment faire ? », Langages 141, 10-27.
Adler, S. (2001). « Les locutions prépositives : questions de méthodologie et de définition », Travaux de linguistique 42-43, 157-170.
Adler, S. (2006). « L’Emploi Absolu d’Expressions de Lieu de type [PREP LE NOM DE]: Ellipse ou Anaphore Associative ? », in Kleiber, G., Schnedecker, C. et Theissen, A. (éds.) La relation partie-tout. Louvain, Paris, Dudley, MA : Peeters. 259 – 272.
Adler, S. (2007). « Locutions Prépositives Notionnelles : Incompatibilités avec l’Emploi Absolu », Le Français ModerneLXXV/2, 209-226.
Adler, S. (2008). « Evénementialité et Partitivité dans les Séquences [PREP LE NOM DE] Temporelles », Langages 169, 67-81.
Adler, S. (2012). Ellipse et Régimes des Prépositions Françaises. Louvain – Paris : Peeters Publishers, Bibliothèque de l’Information Grammaticale 64.
Bally, Ch. (1950). Linguistique générale et linguistique française, Berne, Francke.
Benninger, C. (2001). « Noms de propriété, noms de sentiment et quantification nominale », Cahiers de l’Université d’Artois 22, 11-25.
Borillo, A. (1997). Aide à l’identification des prépositions complexes de temps et de lieu. Faits de langue 9, 173-184.
Bronckart, J.-P. (1996) « Genres de textes, types de discours et opérations psycholinguistiques », Enjeux 37/38, 31-47.
Combettes, B. (1988). Pour une grammaire textuelle,Bruxelles, De Boeck/Duculot.
Condamines Anne (2005). « Anaphore nominale infidèle et hyperonymie : le rôle du genre textuel », Revue de Sémantique et Pragmatique 2005, 23-42.
Fagard, B. & De Mulder, W. (2007). « La formation des prépositions complexes : grammaticalisation ou lexicalisation ? » Langue française 156, 9-29.
Gross, G. (2006). « Sur le statut des locutions prépositives ». Modèles linguistiques 53, 33-50.
Kleiber, G., 2001, L’anaphore associative, Paris, PUF.
Maingueneau, D. (2005). « Réflexions sur la “grammaire du discours” au collège », Le français aujourd’hui 148, 47-54.
Melis, L. (2003), La préposition en français. Ophrys, Paris.
Stosic, D. (2012). « En passant par : une expression en voie de grammaticalisation ? » CORELA Langue, espace, cognition https://journals.openedition.org/corela/2844 (consulté le 2.1.2021)
Stosic, D. et Fagard, B. (2019). « Les prépositions complexes en français : pour une méthode d’identification multicritère », Revue Romane, Les prépositions complexes dans les langues romanes.
Zribi-Hertz, A. (1985). « Trou structural, catégorie vide, ellipse structurale, pronom nul : quatre concepts à préciser », Modèles linguistiques 7/1, 57-71.
[1] Fagard et de Mulder (2007 : 9) utilisent la désignation de « préposition complexe » pour désigner les constructions présentant un certain degré de figement. L’étiquette « locution prépositionnelle » est réservée, par eux, aux constructions non figées ayant la structure [Préposition (+ article) + Base + Préposition]. Ils utilisent Base et non N dans le schéma, parce que leur étude englobe aussi des noyaux autres que nominaux.
Replonger l’histoire de quelques instants dans les tendres souvenirs de l’enfance : (l’)histoire de comme préposition complexe
Anne Le Draoulec & Josette Rebeyrolle
Dans la présente étude, nous nous proposons d’examiner le fonctionnement syntaxique et sémantique de l’expression histoire de lorsqu’elle est suivie d’un syntagme nominal dont la tête nominale est un nom de temps (SNtemp), dans des énoncés du type :
(1) Puis-je quand même trouver un travail, histoire de deux ou trois mois ? (Forum du site www.routard.com)
(2) Au départ, quand j’ai commencé à bosser avec mon frère, je lui avais juste demandé de me filer un coup de main l’histoire de deux ou trois semaines. (Interview dans la rubrique sport du site www.lefigaro.fr)
Cette construction où histoire de (éventuellement précédé de l’article défini) est suivi d’un SNtemp n’a fait l’objet d’aucune étude linguistique, et n’est mentionnée dans aucun dictionnaire. Seule la construction avec un infinitif (plus largement attestée) est envisagée, dans des emplois du type de :
(3) Je vous les cèderais pour un morceau de pain, histoire de vous rendre service (Courteline, Linottes, Pendule, 1890, p. 182 – cité par le TLF)
La séquence histoire de est, dans cette configuration, classiquement catégorisée par les dictionnaires comme « locution prépositive », et mise en équivalence avec pour et afin de. L’équivalence de fonctionnement avec celui d’une préposition est d’ailleurs ce qui, selon Mélis (2003), participe plus généralement à garantir le statut de locution prépositive : ce statut est dès lors acquis pour histoire de, mentionné à côté de face à (Mélis, 2003 : 107) pour illustrer la classe des locutions prépositives à base nominale.
Ce statut de locution prépositive est en revanche contesté par Legallois (2007)[1] dont l’argumentation s’appuie, d’une part, sur l’identité du rôle fonctionnel de histoire de et histoire que (ce qui, selon l’auteur, ne permet pas de faire une différence de nature entre locution prépositive et locution conjonctive) ; et d’autre part sur le fait que le complémenteur dene serait pas véritablement constitutif de la séquence (ce qui amène l’auteur à rejeter le statut même de locution).
Notre objectif sera double. Il sera d’abord de montrer que, contrairement à ce qu’affirme Legallois (2007), histoire de est bien une locution prépositive (ou bien encore « locution prépositionnelle », ou « préposition complexe »), dont nous nous attacherons à préciser les particularités morphologiques, syntaxiques et sémantiques. Notre second objectif sera plus proprement sémantique et consistera à explorer ce que fait (l’)histoire de par rapport à l’espace de ou le temps de, qui en certains points peuvent lui être comparés (plus particulièrement dans le cas où les séquences en question sont suivies d’un SNtemp plutôt que d’un infinitif).
Dans la première partie de notre étude, nous commencerons par examiner – et écarter – rapidement les arguments déployés en défaveur du statut de locution prépositive de histoire de. Puis, afin de mieux caractériser le fonctionnement de la séquence en termes de conformité à la classe des prépositions complexes, nous lui appliquerons les critères d’identification mis au jour par Stosic & Fagard (2019) – ou plus précisément les seuls critères qualitatifs, à l’exclusion des critères quantitatifs dont l’application à histoire de ne serait pas pertinente. Au regard de ces critères qualitatifs, nous montrerons que, s’il manque à histoire de (à l’instar de face à ou grâce à) d’être précédé d’une préposition initiale pour être considéré comme une préposition complexe canonique, la séquence n’en présente pas moins (comme les deux autres susmentionnées) un fonctionnement prototypique de préposition complexe. Nous comparerons les séquences histoire de et l’histoire de, considérant l’absence d’article dans la première comme un signe de figement supplémentaire par rapport à la seconde (laquelle n’est admise que suivie d’un SN). Au-delà de cette question de la présence ou non d’un article dans la séquence, nous nous contenterons de mentionner ici quelques résultats de l’application des divers critères qualitatifs. D’abord, amoindrissant la prototypicalité de la séquence comme préposition complexe : l’impossibilité́ de coordination de (l’)histoire de avec une autre préposition, la possibilité d’insérer un modifieur adverbial, avec pour celui-ci une assez large possibilité de variation (cf. histoire, par ailleurs, de / histoire notamment de / histoire surtout de…), ou encore le fait que la nature sémantique du noyau nominal – histoire, donc – n’ait trait ni à l’espace, ni à une action, ni à aucune relation logico-sémantique. Ensuite, allant au contraire dans le sens de la prototypicalité : la présence de la préposition finale de, l’impossibilité d’anaphorisation du complément à l’aide d’un possessif, l’impossibilité d’insertion d’un modifieur adjectival, l’absence de référentialité du noyau nominal et l’opacité de la séquence. On notera également, allant dans le même sens d’un figement lexical de la séquence, une extension de ses emplois témoignant d’une désémantisation du nom histoire : ainsi, non seulement le complément peut être aussi bien un infinitif (histoire de rire) ou un SN ((l’)histoire d’une petite minute), mais le SN peut être formé, non pas à partir d’un nom de temps comme on a vu jusqu’ici, mais à partir de noms plus divers, comme dans les exemples suivants :
(4) jouer avec les textures, les couleurs… proposer de s’approprier la nature, un peu, juste histoire d’un bonheur partagé. (Magazine en ligne www.artmajeur.com)
(5) On y achète de la vraie viande à emporter ou on s’y assoit pour un apéro, juste histoire d’un verre de vin 100% Argentin. (Blog argentine-info.com)
La seconde partie de l’étude visera à mieux circonscrire les spécificités sémantiques de la séquence (l’)histoire de en la comparant avec les séquences concurrentes le temps de et l’espace de (où la présence initiale de l’article est obligatoire). Dans cette comparaison, le cas où le complément est un infinitif sera rapidement écarté, dans la mesure où les divergences de fonctionnement sont flagrantes. D’une part en effet, seuls histoire de et le temps de admettent un tel complément, cf. (6) ou (7) versus (8) :
(6) On a bavardé un peu, histoire de faire connaissance
(7) On a bavardé un peu, le temps de fumer une cigarette
(8) *On a bavardé un peu, l’espace de fumer une cigarette.
D’autre part, alors que le temps de suivi d’un infinitif permet d’exprimer une durée (avec un sémantisme temporel comparable à celui qu’aurait le temps de suivi d’un SN – cf. le temps d’une cigarette), histoire de suivi d’un infinitif exprime non pas une durée mais une idée de finalité / causalité (cf. Legallois 2007).
La seule configuration où les trois séquences sont comparables (quoiqu’avec une moindre fréquence d’emploi pour histoire de) est ainsi la configuration où elles sont suivies d’un SN – configuration dans laquelle elles introduisent un complément de durée, et admettraient un remplacement par la simple préposition temporelle pendant. Dans le cadre de la présente étude, nous nous limiterons au cas où ce SN est formé sur la base d’un nom de temps, dans des séquences du type de (l’)histoire / le temps / l’espace d’une minute. En nous appuyant sur Le Draoulec (2019), qui déjà comparait le temps de et l’espace de, et mentionnait (p. 123) l’affinité particulière que semble entretenir espace (contrairement à temps) avec l’expression de la brièveté, nous mettrons en évidence que (l’)histoire de, beaucoup plus nettement encore que l’espace de, favorise l’expression de petites quantités de temps. Nous en prendrons pour principale preuve que la séquence est très fréquemment associée à des éléments minimisants tels que juste, deux ou trois (qu’on a déjà rencontrés plus haut), quelques, petit, ne serait-ce que (cf. ci-dessous) :
(9) J’avais très envie de revoir le film cette année, une façon indéniable de replonger l’histoire de quelques instants dans les tendres souvenirs de mon enfance (Blog littéraire lapapotelivresque.wordpress.com)
(10) Et bien oui je me suis remise au tricot l’histoire d’une petite demi heure et voila ce que ça a donné (Blog crea-diddlindsey.over-blog.com)
(11) Mais, comme chaque sollicitation esthétique possède le pouvoir d’éveiller l’individu sur les émissions de sa sensibilité, ne serait-ce que l’histoire d’un bref instant, il se trouve exposé à la tentation d’une esthétique (article de philosophie sur le portail cairn.info)
Cette minimisation de l’intervalle de temps associé à (l’)histoire de peut être mise en parallèle avec le caractère « inconsistant » du procès qui suit la séquence, dans le cas où celle-ci se construit avec un infinitif (caractère « inconsistant » au sens où le procès en question « ne possède pas d’effets ou de conséquences notoires », cf. Legallois, 2007 : 70).
Références bibliographiques
Legallois, D. (2007), « Le connecteur histoire (de) au regard de ses occurrences dans Frantext », Syntaxe et sémantique8/1 : 61-74.
Legallois, D. (2006), « Détermination sémantique, contraintes syntagmatiques, histoire de comprendre un peu) le figement linguistique », in J. François et S. Mejri (dir.), Composition syntaxique et figement lexical, Bibliothèque de Syntaxe et Sémantique, Caen, Presses universitaires de Caen, 165-186.
Le Draoulec, A. (2019), « (L’)espace de versus (le) temps de », Scolia 33 : 99-123.
Melis, L. (2003), La préposition en français, Ophrys, Paris.
Stosic, D., Fagard, B. (2019), « Les prépositions complexes en français : pour une méthode d’identification multicritère »,Revue Romane 54/1 : 8-38.
[1] Legallois (2007) fait suite à une première étude consacrée à histoire de (Legallois (2006), où ce statut n’était pas encore remis en cause.
Petite grammaire des choses sans importance : à partir des locutions expressives histoire de + Inf.,pour de rire
Dominique Legallois
L’objectif de cette communication est l’analyse de deux locutions prépositionnelles : histoire de (+inf.) et pour de rire. Rapprocher dans une étude ces locutions se justifie pour les raisons suivantes, qui seront détaillées dans la communication :
- Elles apparaissent grosso modo à la même période : si Google Livres donne des occurrences dès le début du 19esiècle, Frantext ne donne pas de résultats avant cette période.
- Si la locution pour de rire est figée, rire est le complément exclusif jusqu’aux années 1830 de histoire de.
- Les deux locutions sont en principe réductibles à la même forme : pour rire. Néanmoins, avec la locution « finale » histoire de, rire a le sens ‘rigoler’, ‘plaisanter’, tandis que pour de rire prend rapidement le sens ‘pour faire semblant’ (d’où son emploi considéré comme privilégié dans les jeux enfantins) et s' »adverbialise » ; pour rire possède également cette acception. Dans cette première occurrence identifiable de pour de rire, il est intéressant de remarquer que pour rire est également employé (ainsi, accessoirement, que rire au nez) :
Jacquinet, avec malice.
– Comme c’est agréable d’être Roi, même pour rire !
Henri.
– Jacquinet aurait-il de l’ambition ?
Jacquinet.
– Ma fine, on dit qu’c’est souvent tout c’qui faut pour s’élever ; et si je désirons queuques petites fonctions, pour de rire aussi, ben entendu, pisque vous n’êtes pas Roi pour tout de bon, ce ne serait que pour me venger de ceux qui me prennent pour un imbécille.
Jacquinet.
– Eh ben ! tout comme aux autres : je sais ben que ça n’y fait rien ; mais c’est égal, on n’ose plus venir vous rire au nez.
Le Baptême de Village, ou le Parrain de Circonstance, vaudeville en un acte, de Michel Joseph Gentil de Chavagnac 1821
- Les deux locutions ont une valeur expressive, d’où leur emploi dans des registres familiers. Pour pour de rire et histoire de rire, Google Livres donne essentiellement des vaudevilles. Pour histoire de rire, Frantext montre que les premières occurrences apparaissent dans les dialogues (de romans) prononcés par des gens du peuple.
- Le statut catégoriel de rire pour les deux locutions est complexe : infinitif ou nom ? le statut de de dans pour de rire vient brouiller l’interprétation infinitive (puisqu’apparaissent ensuite, pour de bon, pour de faux, pour de vrai). Par ailleurs, cette ambiguïté n’a pas été sans jouer de rôle dans le développement de histoire de : rire a été « sélectionné » d’abord pour son statut nominal et a ensuite été réanalysé comme infinitif.
- La forme « c’est » (c’est pour de rire, c’est histoire de rire) est très présente dans les premiers emplois, et s’estompe rapidement par la suite. Avec histoire, l’article est encore employé dans les tout premiers emplois
Tranchet :
Ce que j’en disais, c’était l’histoire de rire un moment
(Misère et gaîté: Comédie en un acte, mêlée de couplets, de Antoine Jean Baptiste Simonnin 1809).
À partir de cet emploi, la forme locutionnelle prépositive histoire de rire s’est détachée. Néanmoins, comme toujours, les choses sont sûrement plus compliquées, car le premier emploi identifié de histoire de apparait déjà sans article et sans « c’est »:
Mad. Endurant :
– Nous sommes seuls, j’ai à vous parler, il y a une demi-heure que je vous cache mon amour, je n’y tiens plus, je suis inquiette ; vous avez eu des raisons avec Sot-Major ?
Braillard :
– Laissez donc, madame, histoire de rire
(Les amours de Braillard, ou tout le monde en vent de Maurice Ourry (1808)).
L’occurrence se comprend, cependant : laissez donc c’était histoire de rire
Identifier l’origine de ces locutions est donc chose complexe, en raison du peu de données – ces formes étant avant tout orales ; il s’agira donc, dans la communication, de proposer quelques hypothèses sur l’apparition de ces deux locutions, de leur concurrence avec pour rire. On mettra ainsi en évidence la possible origine de histoire de + inf. (Legallois, 2012),
locution dont les compléments se diversifient de façon spectaculaire à partir des années 1830 : histoire de blaguer, histoire de passer le temps, etc. A ce même moment, d’ailleurs, deux autres locutions prépositionnelles sont en voie de disparition : par manière de et en manière de (Legallois et Schnedeker 2008) dont l’un des compléments les plus fréquents est justement plaisanterie ou encore rire :
Heureusement que dans tout ceci il n’y avait rien de vrai : ce n’était qu’une facétie à l ‘Alcibiade, un petit grain de sel attique qu’on nous avait jeté à la face par manière de rire. Le mal n’était pas grand, et je m’en réjouis presque.
(Voyage à Constantinople par l’Italie, la Sicile et la Grèce .Jacques Boucher de Crèvecoeur de Perthes · 1855).
n’est- il pas honteux pour des gens comme il faut de bien parler l’allemand ? Mais il est bon de pouvoir lancer de temps en temps un mot tudesque en manière de plaisanterie, cela est même très chic
Revue contemporaine (Paris. 1858)
Il conviendra donc d’interroger les relations entre toutes ces locutions, d’interroger leurs spécificités et leurs complémentarités
Adler S., 2001, « Les locutions prépositives : questions de méthodologie et de définition », Travaux de Linguistique, 42-43, 157-170.
Fagard, B. (2012), Prépositions et locutions prépositionnelles : la question du renouvellement grammatical. Travaux de linguistique 64(1), 161–189.
Fagard, B.& W.De Mulder (2007):La formation des prépositions complexes: grammaticalisation ou lexicalisation ? Langue française,156, pp. 9-29.
Legallois D. (2012) «From grammaticalization to expressive constructions : the case of histoire de + inf. » In Bouveret M. et Legallois D., Constructions in French, Amsterdam, Benjamins, p.257-283
Legallois D. et C.Schnedecker (2008) «Par manière de/en manière de : éléments de description diachronique et synchronique», in Acte du Colloque Autour de la préposition, Presses universitaires de Caen, 117-128
Gross, G. (2006): Sur le statut des locutions prépositives. Modèles linguistiques,53, pp.33-50
Leeman, D. (2007), De la préposition à la locution prépositionnelle. Modèles linguistique, 55, 7–15.
Melis L.( 2003) La préposition en français, Gap, Paris, Ophrys.
Le paradigme des prépositions complexes en français
Dejan Stosic
L’objectif principal de cette communication sera de dresser un profil général du paradigme des prépositions complexes (PrépComp) en français contemporain à travers une caractérisation morpho-syntaxique, lexicale et sémantique d’un large éventail d’expressions candidates à la classe. Cette tâche sous-entend trois pré-requis fondamentaux, à savoir qu’il faut disposer i) d’une définition solide des unités en question, ii) de critères d’identification fiables, et iii) d’un relevé aussi exhaustif que possible des membres du paradigme, les trois étant étroitement liés. L’hypothèse sous-jacente à ce travail est qu’une description globale du (sous-)système des PrépComp doit conduire, par un effet de retour, à une meilleure caractérisation des unités qui le composent et des schémas structurels qui le sous-tendent.
En ce qui concerne les pré-requis mentionnés, l’abondante littérature sur les prépositions en français (mais aussi dans d’autres langues) fait apparaître que seul le premier est à considérer comme (relativement) acquis, les deux autres – bien que largement discutés depuis plusieurs décennies – continuent à poser d’importantes difficultés. En effet, le consensus est loin d’être atteint lorsqu’il s’agit de critères permettant de distinguer de manière sûre des séquences libres et des PrépComp (cf. notamment Borillo 1997, Adler 2001, 2007, Melis 2003, Fagard & De Mulder 2007, Leeman 2007, Lauwers 2014, Stosic & Fagard 2019) et, à ce jour, aucun inventaire complet des PrépComp en français n’est mis à la disposition de la communauté scientifique (voir cependant des tentatives dans Delaunoy 1967, Gaatone 1976, Borillo 1991, 1997, 2000, Melis 2003, Le Pesant 2006). Dans le présent travail, je m’appuierai d’une part sur la définition des PrépComp proposée par Fagard et al. (2020a, 2020b) et, d’autre part, sur un inventaire de 660 séquences candidates à la classe, établi à partir de différentes sources lexicographiques (TLFi, Le Petit Robert, Larousse) et de la littérature spécialisée (cf. notamment Delaunoy 1967, Gross 1981, 2006, Borillo 1997, 2002, Melis 2003, Le Pesant 2006, Lauwers 2014, Stankovic 2020, Stosic en préparation). Bien que visant l’exhaustivité, le relevé en question est à prendre comme une base de départ hypothétique en vue d’un examen plus approfondi du paradigme des PrépComp, et ceci pour deux raisons. Premièrement, en plus d’expressions dont le statut de PrépComp est largement avéré et admis dans la tradition grammaticale, en lexicographie et en linguistique (ex. à travers, par rapport à, au sein de), on en trouve d’autres qui mériteraient une analyse plus poussée avant d’être intégrées à ou écartée de la liste (ex. à valeur de, sur le bord de). Deuxièmement, il est possible que certaines expressions ayant potentiellement leur place dans la classe ne soient pas répertoriées. Bien qu’imparfaite, une telle base empirique est indispensable pour circonscrire les contours de la classe. Cela m’amène à adopter l’idée défendue, entre autres, par Mélis (2003) et Stosic & Fagard (2019), que la sous-classe des PrépComp doit être envisagée comme un continuum entre des membres centraux ou prototypiques, entièrement figés et sémantiquement opaques, et des membres marginaux, assez libres sur le plan syntagmatique et sémantiquement transparents. Entre les deux, on identifie, d’après Melis (2003 : 115), « une zone dans laquelle se situent des suites plus ou moins figées et plus ou moins opaques qui entretiennent des relations plus ou moins systématiques avec les prépositions simples ».
Pour ce qui est de la définition, les PrépComp sont généralement considérées comme des équivalents fonctionnels des prépositions simples du point de vue distributionnel et sémantique, mais qui s’en distinguent par leurs propriétés morphologiques étant donné qu’elles présentent une structure interne composite (cf. Melis 2003: 112-114). Ainsi, aussi bien les prépositions simples que les prépositions complexes sont des unités invariables qui établissent un lien de dépendance entre le syntagme dont elles sont la tête et un autre constituant. Traditionnellement définies comme « relateurs » (Pottier 1962), elles entrent dans un schéma ternaire (A R° B) marquant la dépendance, à la fois syntaxique et sémantique, d’un élément A (recteur) par rapport à un élément B (complément). Nous pouvons observer ce parallélisme dans les exemples (1) et (2) où, tout comme pour, l’expression à cause de : a) introduit un complément, b) rattache le constituant ainsi formé au verbe recteur démissionner, et c) spécifie une relation sémantique entre la structure intégrante et l’élément intégré (cf. Fagard et al. 2020a, 2020b Stosic & Fagard 2019).
- Le chef de la police de New-York démissionne pour une affaire de corruption. (Le Monde)
- En Écosse, le ministre des Finances démissionne à cause d’une affaire de harcèlement. (Le Figaro)
Selon Fagard et al. (2020a : 12-13, 2020b : 40-41), la complexité morphologique des PrépComp permet d’envisager une redistribution des trois rôles cumulés par une préposition simple sur les éléments formants des PrépComp. En effet, à la différence d’une préposition simple, en l’occurrence pour, qui cumule les trois fonctions, une préposition complexe « canonique » (ex. à cause de) distribue celles-ci sur trois éléments différents : une préposition simple finale lie le complément (de), une autre préposition simple initiale rattache l’ensemble au constituant recteur (à), et un élément central de nature lexicale est porteur de la spécification sémantique de la relation établie (cause). La grande majorité des PrépComp en français se conforme à ce schéma de construction général, qui peut être noté [P1 NoyauLexical P2] et qui se décline en une quinzaine de patrons morpho-syntaxiques, dont seuls quelques-uns sont productifs. C’est ce que révèle l’inventaire de 660 items mentionné ci-dessus (voir aussi Stosic & Fagard 2019).
Les patrons de formation en question peuvent être classés selon la nature du noyau lexical en cinq types. Le graphique 1 montre que la grande majorité des PrépComp recensées (85%) sont formées à partir d’un nom, comme dans beaucoup d’autres langues (cf. Fagard et al. éds 2020), et que quatre autres catégories participent à leur formation : les adverbes, les prépositions (simples), les adjectifs et les verbes. Plus précisément, la très grande majorité des PrépComp est formée sur la base de la combinaison d’une préposition et d’un nom suivi de la préposition de. En effet, on répertorie 452 items relevant de ce modèle de formation : la plupart du temps — dans 306 cas —, le nom est précédé d’un déterminant, correspondant généralement à l’article défini. Le graphique 2 présente les principaux schémas de construction des PrépComp recueillies à des fins de cette étude.
Graphique 1 Graphique 2
Le même inventaire fait apparaître, sans surprise, l’importance des prépositions simples dans la formation des PrépComp. Ainsi, 593/660 PrépComp commencent (ex. au bord de, à travers) et 618/660 se terminent par une préposition simple (ex. au fond de, face à) ; seuls 7 items du relevé ne comportent aucune préposition dans leur structure (ex. il y a, étant donné) et 560 d’entre elles en intègrent deux (ex. par rapport à, au sein de). Le tableau suivant illustre les principales prépositions initiales et finales en fonction du nombre de PrépComp formées :
Tableau 1
Pour revenir au noyau lexical des PrépComp recensées, environ 340 noms de sémantisme varié forment au total 560 items. Environ deux tiers de ces noms n’apparaissent que dans une seule formation, ce qui peut être interprété comme indice de la nature lexicale des PrépComp. Environ 80 noms forment deux ou trois PrépComp et une quinzaine en forment plus : 4 (bas, cours, fait, manière, travers), 5 (bout, compte, égard, mesure) ou 6 (côté, fin). Du point de vue sémantique, ces noms noyaux relèvent d’une quinzaine de domaines différents. Le domaine sémantique de l’espace a fourni le plus grand nombre de noms formants, qui ont trait essentiellement à la partition (ex. bas, bord, côté, fond, intérieur, sommet, cœur, face, pied, sein, dessus) (conformément à Svorou 1994, voir aussi Borillo 1997, 2000), à la direction et à l’orientation (ex. biais, direction, droit, nord, est, travers), à la géométrie (ex. axe, contact, niveau, point), etc. Les noms d’action constituent la deuxième sous-classe la plus exploitée dans la formation des PrépComp ; la plupart d’entre eux sont dérivés à partir de verbes (ex. instigation, comparaison, pression, recherche), mais on y trouve également des formes verbales substantivées comme le participe passé (ex. vu, tombé, reçu, revu) ou l’infinitif (ex. sortir, quitter, tomber, lever). Viennent ensuite, dans des proportions beaucoup moins importantes, les noms relationnels (ex. proportion, rapport, inverse, fonction), les noms exprimant la manière (ex. mode, façon, manière, guise), ceux relevant du domaine psychologique (ex. envi, peine, peur, dépit), les noms d’états (ex. absence, insu, manque), les noms d’idéalités (ex. idée, fait, terme, signe) (cf. Flaux & Stosic 2015) et de temps (ex. début, fin, moment, temps, veille, aube).
Dans la dernière partie de ma communication, je dresserai l’éventail des sens véhiculés par les PrépComp en français afin de montrer quels types de relations sémantico-logiques les expressions en question prennent en charge. Si les sens spatial (ex. jusqu’à, face à), temporel (ex. au cours de, à la fin de) et causal (ex. à cause de, en raison de) sont exprimés par le plus grand nombre d’items (respectivement 230, 100 et 50), bien d’autres valeurs occupent une place importante : thématisation (ex. quant à, concernant), comparaison (ex. en comparaison avec, à l’istar de), instrument (ex. grâce à, au moyen de), finalité (ex. en vue de, en faveur de), opposition (ex. contrairement à, à l’inverse de), exclusion (ex. à l’exception de, mise à part), agentivité (ex. de la part de, sur ordre de), fondement (ex. sur la base de, en vertu de)… Une telle grille est indispensable pour mieux cerner le rôle et la profusion grandissante des PrépComp dans le système de la langue depuis la période des Lumières (cf. Fagard et al. 2020b : 59, 2020c :484-486), mais aussi pour positionner celles-ci par rapport au paradigme des prépositions simples.
Références bibliographiques
Adler, S. (2001), Les locutions prépositives : questions de méthodologie et de définition. Travaux de linguistique, 42-43,1, 157-170.
Adler, S. (2007), Locutions prépositives temporelles et modes d’anaphorisation. In D. Trotter (éd.), Actes du XXIVe Congrès International de linguistique et Philologies Romanes. Niemeyer, Tübingen, 495-508.
Borillo, A. (1991), Le lexique de l’espace : prépositions et locutions prépositionnelles de lieu en français. In L. Tasmowski & A. Zribi-Hertz (éds.), Hommage à N. Ruwet. Gand, Communication & Cognition, 176-190.
Borillo, A. (1997), Aide à l’identification des prépositions complexes de temps et de lieu. Faits de langue, 9, 173-184.
Borillo, A. (2000), Degrés de grammaticalisation : des noms de partie aux prépositions spatiales. Travaux linguistiques du CERLICO, 13, 257–274.
Borillo, A. (2002), Il y a prépositions et prépositions. Travaux de Linguistique, 42-43, 141-155.
Delaunoy, A. (1967). Le bon emploi de la préposition en français. Namur, Wesmael-Charlier.
Fagard, B. & De Mulder, W. (2007), La formation des prépositions complexes : grammaticalisation ou lexicalisation ? Langue française, 156, 9-29.
Fagard, B., Pinto de Lima, J., Stosic, D. & Smirnova, E. (2020a), Complex Adpositions and Complex Nominal Relators.In Fagard et al. (Eds), Complex adpositions in European Languages. Berlin, De Gruyter, 1-30.
Fagard, B., Pinto de Lima, J., Stosic, D. & Smirnova, E. (éds) (2020), Complex adpositions in European Languages. Berlin, De Gruyter.
Fagard, B., Smirnova, E., Stosic, D. & Pinto de Lima, J. (2020c), Complex adpositions in Europe and beyond: A synthesis. In Fagard et al. (éds), Complex adpositions in European Languages. Berlin, De Gruyter, 473-495.
Fagard, B., Stosic, D. & Pinto de Lima, J. (2020b), Complex adpositions in Romance languages. In Fagard et al. (éds), Complex adpositions in European Languages. Berlin, De Gruyter, 33-64.
Flaux, N. & Stosic, D. (2015), « Pour une classe des noms d’idéalités », Langue française 185, 43-57.
Gaatone, D. (1976). Locutions prépositives et groupes prépositionnels. Linguistics, 167, 15-34.
Gross, G. (1981). Les prépositions composées. In C. Schwartz (Ed.), Analyse des prépositions. Tübingen, Max Niemeyer Verlag.
Gross, G. (2006), Sur le statut des locutions prépositives. Modèles linguistiques, 53, 33-50.
Lauwers, P. (2014). From lexicalization to constructional generalizations. In H. Boas & F. Gonzálvez-García (Eds.), Romance Perspectives on Construction Grammar (pp. 79–111). Berlin: De Gruyter.
Leeman, D. (2007), De la préposition à la locution prépositionnelle. Modèles linguistique, 55, 7–15.
Leeman, D. (éd.) (2007), Prépositions et locutions prépositionnelles. Modèles linguistiques, 55.
Le Pesant, D. (2006), Classification à partir des propriétés syntaxiques. Modèles linguistiques, 53, 51-74.
Melis, L. (2003), La préposition en français. Ophrys, Paris.
Pottier, B. (1962) Systématique des éléments de relation. Paris, Klincksieck.
Stankovic, I. (2020). Analyse outillée des prépositions complexes en français et en serbe. Mémoire de master 1. Toulouse, Université Toulouse Jean Jaurès.
Stosic, D. (en préparation), Les prépositions complexes en français.
Stosic, D. & Fagard, B. (2019), Les prépositions complexes en français : pour une méthode d’identification multicritère. Revue Romane, 54 (1), 8-38.
Svorou, S. (1994). The Grammar of Space. Amsterdam/Philaldelphia: John Benjamins.
Extending the Semantic Cartography Hypothesis beyond French Spatial Prepositions
Francesco-Alessio Ursini, Keith Tse & Tong Wu
A wealth of research of French spatial prepositions has uncovered their syntactic distribution and morphological structures (Borillo 2000, 2001; Melis 2003; Fagard 2006, 2008, 2009a, b, 2010, 2012; Fagard & De Mulder 2007, 2010; Fagard & Sarda 2009; Le Pesant 2011, 2012; Fagard, Pinto de Lima, Stosic and Smirnova 2020). A general consensus is that one can partition the category into simple and complex prepositions. Simple prepositions (e.g à) are heads governing the NP denoting the landmark object, or ground (Talmy 2000: Ch. 1). Complex prepositions include Internal Location Nouns (ILN’s) to specify which location the located entity or figure occupies, with respect to the ground (e.g. l’intérieur: Borillo 1988, 1998; Aurnague 1996, 1998). Both types display similar but not identical grammatical properties.
Formal semantic research builds on cognitive linguistics results (Vandeloise 1987, 1988, 1991, 1994, 2003) and has also developed fine-grained analyses of this category (Aurnague 1991; Vieu 1991; Aurnague & Vieu 1993; Aurnague et al. 1997, 2000, 2007; Stosic 2007). A key proposal is that French spatial prepositions denote relations among objects and the locations or space portions they occupy. Building on these insights, Aurnague & Vieu (2013, 2015) introduce the Semantic Cartography hypothesis. That is, a core set of prepositions denotes functional relations (e.g. à), i.e. relations between figure and ground that involve mechanical or affordance-based aspects (e.g. support, interaction). Instead, complex prepositions can denote internal and external regions, mostly via ILN’s (e.g. à l’intérieur de and à l’extérieur de, respectively).
The generative syntax-based Ursini & Tse (2021) builds on related formal proposals (Zwarts 1997; Zwarts & Winter 2000; Aurnague, Bras, Vieu & Asher 2001, Svenonius 2008). This work suggests that the Semantic Cartography hypothesis reflects the morphological interaction between ILN’s and prepositions, in French. The work proposes to add a fourth type, projective prepositions, to this Cartography. The work also observes that one cannot find an exact mapping among morphological and semantic types. For instance, simple but di-syllabic preposition devant belongs to the projective type. Crucially, the projective type can be identified because the PPs headed by this type of prepositions can distribute with Measure Phrases (henceforth: MPs), thus “measuring” the complex relation between figure and ground.
The work supports these claims via a written elicitation task in which native speakers of French (N=30) evaluated test sentences involving preposition types on a 5-point Likert scale (“1” being unacceptable, “5” being perfect). Examples (1)–(4) report some of the results from this study. The fourth line in each example reports the average value for each example and individual speakers’ scores, e.g. “14” being 4 speakers answering “1” to an example (de Clerq & Haegeman 2018). We consider examples with average scores higher than “4” as being “near perfect”, between “3” and “4” as acceptable, and those approximating “2” as unacceptable:

The picture that can be summarised from these examples is as follows. Functional and internal/external region prepositions head PPs that generally do not distribute with MPs (respectively à la voiture in (1), à l‘intérieur/extérieur de la voiture in (2)–(3), viz. the “#” symbol). Intra-speaker variation is attested for items such as à l‘extérieur de: for some participants (N=7), this preposition belongs to the projective type, though for most participants it belongs to the external region type. For almost all speakers, projective prepositions head PPs that can distribute with MPs (e.g. dix mètres devant la voiture in (4), dix mètres an MP). Simple prepositions à and devant thus respectively belong to the functional and projective semantic types; complex prepositions à l‘intérieur/extérieur de, to the region types.
Crucially, Ursini & Tse (2021) diverges from previous generative accounts (e.g. Roy 2006; Svenonius 2008, 2010; Gehrke 2008; Real-Puigdollers 2013). It proposes that simple à lacks an ILN, and can thus only introduce functional relations. The ILN’s l’intérieur/l’extérieur refer to regions defined with respect to the ground; devant to a projection/axis. Hence, complex prepositions depend on the sense of their ILN’s for their semantic type (internal/external region, projective) and distribution with MPs. Like Aurnague & Vieu (2015), Ursini & Tse (2021) also proposes that the Semantic Cartography hypothesis has cross-linguistic import. However, it suggests that one must attest categories corresponding to simple and complex prepositions, and that the mapping between morphological and semantic types can be nuanced.
The goal of this presentation is to confirm this hypothesis on Italian, Chinese and Korean. We choose these languages because they include different sets of categories related to prepositions and ILN’s (cf. Hagège 2010; Libert 2013). Thus, they offer a broader testing ground for the extended Semantic Cartography hypothesis. We achieve this goal in two steps. First, we show that the simple/complex distinction can be extended to these languages once we individuate categories behaving like ILN’s and prepositions (cf. also Bybee 2006). Second, we show that simple categories usually denote functional types, and that ILN-like categories are part of complex categories, and can determine semantic types and distribution with MPs. Our data and reasons are as follows.
Italian resembles French in having a clear-cut set of morphologically simple prepositions (Bottari 1985a, b; Rizzi 1991; Ganfi & Piunno 2017). However, Italian ILN’s may have de-verbal or adjectival origins or have undergone univerbation with prepositions (Giacalone Ramat 1994; Voghera 1994, 2004; Casadei 2011; Franco 2016, 2018). The picture regarding Italian semantic types has been studied in Ursini & Wu (2021), and also involves data from a written elicitation task (N=50). The results can be approximated as follows. Italian simple prepositions (e.g. a in (5)) denote functional relations and cannot distribute with MPs. Complex prepositions can denote internal and external region types via de-verbal adjectives (all’interno/esterno di in (6)–(7)). Most but not all complex prepositions include ILN’s, and can distribute with MPs (e.g. di fronte a, fronte in (8)):

Mandarin includes prepositions also distributing as co-verbs (Chao 1968: Ch. 28; Peyraube 1980, 1994; Sun 2006: Ch. 30; Huang, Li & Li 2009: Ch. 6; Zhang 2017). However, it also includes fangweici ‘localisers’, a category of nominal modifiers following ground NPs (Li & Thompson 1981: Ch. 26; Liu 1994, 1998; Peyraube 2003; Chappelle & Peyraube 2008; Huang 2009; Djamouri et al. 2013). Though an ample debate exists on whether localisers can be analysed as postpositions or as “spatial” nouns, it is generally assumed that the combination of prepositions and localisers, along with ground NPs, forms a discontinuous PP. Thus, the discontinuous combination of preposition and localiser is often analysed as a language-specific counterpart to complex prepositions (Djamouri et al. 2013, Zhang 2017).
For Mandarin, Ursini, Long & Zhang (2020) offer an analysis based on the same type of elicitation task used for Italian and French (with N=31). Though the results are not as clear-cut as those for Italian and French, the following picture emerges from this study. Prepositions can distribute with place names as ground NPs, and in such cases they belong to the functional type (e.g. zai in (9)). With other ground NP types, compound localisers become obligatory, usually follow the relational element de, and determine the sense type of the whole discontinuous PP. For instance, li-tou, wai-tou in (10)–(11) denote internal/region types. Qian-mian in (12) denotes a region type, and its PP combines with an MP. More in general, other compound localisers follow similar patterns (e.g. qian-fang, lit. ‘front-axis’):
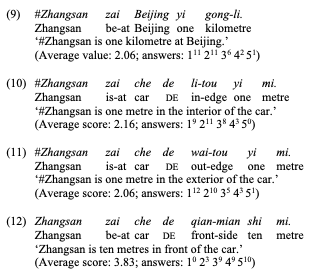
Korean includes spatial particles (i.e. case markers) attaching to ground NPs (Chang 1996: Ch. 3; Kim & Choi 2004; Son 2006; Kang 2012; Kim 2016: Ch. 32), and “spatial” nouns following particle and ground NP (Rhee 2004, 2008; Song 2006; Choi-Jonin 2008; Ko 2008, 2013; Bayk 2013, 2019). These works also suggest that spatial particles/case markers act as approximate counterparts of prepositions in Korean, and that spatial nouns can be treated as a category slowly grammaticalising into postpositions (e.g. “postpositionoids” in Rhee 2004, 2008; Bayk 2013, 2019). Thus, the combination of spatial particle and noun is considered as carrying the same morpho-syntactic functions of complex prepositions.
The preliminary picture that we offer here is based on Ursini & Baik (2021), also via an elicitation task (N=12). The results are as follows. Korean ground NPs only marked via particles (or “simple” ground NPs) mostly denote functional relations (-ey in (13)). Post-modifier nouns can create “complex” ground NPs and partially determine the semantic status of this phrase, and thus its distribution with MPs. This is however possible only when the spatial particle attaching to a ground NP corresponds to an ablative case maker. For instance,
-an-/-pakk- denote internal/external prepositions and block MPs (cf. (14)–(15)) when following locative -ey. Instead, -pah- denotes a projective type once it follows the ablative particle -ulopwuthe, and the corresponding PP thus licenses distribution with MPs (cf. (16)):

We therefore conclude that the extended Semantic Cartography hypothesis holds for these three languages, though in a nuanced manner. First, Italian and Mandarin prepositions plus Korean particles act as counterparts of French simple prepositions. Second, Italian nouns and adjectives, Mandarin localisers, and Korean spatial nouns act as counterparts of ILN’s, and can determine the semantic type of their complex category. MPs across each language then individuate PPs headed by projective complex categories (i.e. prepositions or case markers). Third, a certain degree of intra-speaker variation exists in each language. Speakers may differ on whether they consider each item broadly belonging to complex prepositions/categories as carrying region or projective senses. Nevertheless, all speakers accept the proposed semantic types as existing in their languages. Time permitting, the presentation will also develop a model-theoretic extension based on previous works (Zwarts & Winter 2000; Aurnague, Bras, Vieu and Asher 2001; Stosic 2007) to formally capture this hypothesis.
References
Aurnague, M. 1991. Contribution à l’étude de la sémantique formelle de l’espace et du raisonnement spatial: La localisation interne en français, sémantique et structures inférentielles. Doctoral Dissertation, Université Paul Sabatier.
Aurnague, M. 1995. Orientation in French spatial expressions: Formal representations and inferences. Journal of Semantics 12(2). 239–267.
Aurnague, M. 1996. Les noms de localisation interne: Tentative de caractérisation sémantique à partir de données du basque et du français. Cahiers de Lexicologie. 159–192. Paris: Centre National de la Recherche Scientifique.
Aurnague, Ml. 1998. Basque genitives and part-whole relations: Typical configurations and dependences. Carnets de grammaire: Rapports internes de l’ERSS. 1–62. Paris: Centre National de la Recherche Scientifique.
Aurnague, M. 2004. Les Structures de l’Espace Linguistique: Regards croisés sur quelques constructions spatiales du basque et du français. Leuven/Paris: Peeters.
Aurnague, M., and D. Stosic. 2002. La préposition ‘par’ et l’expression du déplacement: Vers une caractérisation sémantique et cognitive de la notion de “trajet”. Cahiers de Lexicologie 81(1). 113–139.
Aurnague, M., K. Boulanouar, J.-L. Nespoulous, A. Borillo, and M. Borillo. 2000. Spatial semantics: The processing of internal localization nouns. Cahiers de Psychologie Cognitive 19(1). 69–110.
Aurnague, M. and L. Vieu. 1993. A three-level approach to the semantics of space. In The Semantics of Prepositions: From Mental Processing to Natural Language Processing, ed. C. Zelinsky-Wibbelt, 395–439. Berlin: Mouton de Gruyter.
Aurnague, M., and L. Vieu. 2013. Retour aux arguments: Pour un traitement relationnel des prépositions spatiales. Faits de Langues 42(1). 17–38.
Aurnague, M., and L. Vieu. 2015. Function versus regions in spatial language: A fundamental distinction. In Neuropsycholinguistic perspectives on language cognition: Essays in honour of Jean-Luc Nespoulous, ed. C. Astésano and M. Jucla, 31–45. New York: Psychology Press.
Aurnague, M., L. Vieu, and A. Borillo. 1997. Représentation formelle des concepts spatiaux dans la langue. In Langage et Cognition Spatiale, ed. M. Denis, 69–102. Paris: Masson.
Aurnague, M., M. Bras, L. Vieu, and N. Asher. 2001. The syntax and semantics of locating adverbials. Cahiers de Grammaire 26(1). 11–35.
Aurnague, M., M. Champagne, L. Vieu, A. Borillo, P. Muller, et al. 2007. Categorizing spatial entities with frontal orientation: The role of function, motion and saliency in the processing of the French Internal Localization Nouns avant/devant. In The Categorization of Spatial Entities in Language and Cognition, vol 20, ed. M. Aurnague, M. Hickmann and L. Vieu, 153–171. Amsterdam: John Benjamins.
Baik, J. 2013. On the Rise of Nominalizers in Korean: Grammaticalization of Cikyeng
‘Boundary’ and Yang ‘Shape’. Procedia – Social and Behavioral Sciences 97. 474–479.
Baik, J. 2019. A Corpus-Based Analysis of the Functional Split of the Lexical Item the ‘ground’ in Korean. The Journal of Linguistics Science 88. 227–250.
Bybee, J. 2006. Language change and universals. In R. Mairal and J. Gil (eds,), Linguistic Universals. Cambridge. Cambridge University Press. 179–194.
Borillo, A. 1988. Le lexique de l’espace: Les noms et les adjectifs de localization interne. Cahiers de Grammaire 13(1). 1–22.
Borillo, A. 1998. L’espace et Son Expression en Français. Gap/Paris: Editions Ophrys.
Borillo, A. 2000. Degrés de grammaticalisation: des noms de parties aux prépositions spatiales. Travaux Linguistiques du Cerlico 13(2). 257–274.
Borillo, A. 2001. Il y a prépositions et prépositions. Travaux de linguistique 42–43(1). 141–155.
Bottari, P. 1985a. Per una ricerca sui sintagmi preposizionali: premesse storiografiche e critiche. Studi e Saggi Linguistici48. 211–256.
Bottari, P. 1985b. Sintagmi locuzionali preposizionali. Rivista di Grammatica Generativa 9–10. 141–214.
Casadei, F. 2001. Le locuzioni preposizionali. Struttura lessicale e gradi di Lessicalizzazione. Lingua e Stile 36(1). 43–80.
Chang, S.-J. 1996. Korean. Philadelphia: John Benjamins.
Choi-J., I. 2008. Particles and postpositions in Korean. In Adpositions: Pragmatic, semantic and syntactic perspectives(Typological Studies in Language 74), eds. D. Kurzon and S. Adler, 133–170. Amsterdam: John Benjamins.
Chao, Y. R., 1968, A Grammar of Spoken Chinese, Berkeley, University of California Press.
Chappell, H., A. Peyraube, 2008. Chinese localizers: Diachrony and some typological considerations. In Space in Languages of China, ed. D. Xu, 15–37. Berlin, Springer.
de Clercq K., and L. Haegeman. 2018. The typology of V2 and the distribution of pleonastic DIE in the Ghent dialect. Frontiers in Psychology 9(1342). doi:10.3389/
fpsyg.2018.01342
Djamouri, R., P. Waltraud, J. Whitman. 2013. Postpositions vs. prepositions in Mandarin Chinese: The articulation of disharmony. In Theoretical Approaches to Disharmonic Word Order, ed. T. Biberauer, and M. Sheehan, 69–101. Oxford: Oxford University Press.
Fagard, B. 2006. Evolution Sémantique des Prépositions dans les Langues Romanes: Illustrations ou contre-exemples de la Primauté du spatial? Doctoral Dissertation, Université Paris VII.
Fagard, Benjamin. 2009a. Prépositions simples et prépositions complexes – problèmes sémantiques. Langages 173(1). 95–113.
Fagard, B. 2009b. Grammaticalisation et renouvellement: conjonctions de cause dans les langues romanes. Revue Roumaine de Linguistique 54(1–2). 21–43.
Fagard, B. 2010. Espace et Grammaticalisation – L’évolution Sémantique des Prépositions dans les Langues Romanes. Paris: Editions Universitaires Européennes.
Fagard, B. 2012. Prepositions et Locutions Prepositionnelles: La question du renouvellement grammatical. Travaux de linguistique 64(1). 161–189.
Fagard, B., and L. Sarda. 2009. Etude diachronique de la préposition dans. In Autour de la Préposition, ed. J. François, É. Gilbert, C. Guimier and M. Krause, 225–236. Caen: Presses Universitaires de Caen.
Fagard, B., and W. De Mulder. 2007. La formation des prépositions complexes: grammaticalisation ou lexicalisation?. Langue française 156(1). 9–29.
Fagard, B., and W. De Mulder. 2010. Devant: Evolution sémantique d’une préposition en français. In Congrès Mondial de Linguistique Française, ed. F. Neveu, V. Muni Toke, J. Durand, T. Klingler, L. Mondada and S. Prévost, 2173–2181. Paris: Institute de la langue Française.
Fagard, B., Pinto de Lima, J., Stosic, D. and E. Smirnova (Eds) (2020), Complex adpositions in European Languages. Berlin, De Gruyter.
Franco, Ludovico. 2018. (Im)proper prepositions in (Old and Modern) Italian. Manuscript, University of Florence.
Giacalone Ramat, A. 1994. Fonti di grammaticalizzazione. Sulla ricategorizzazione di verbi e nomi come preposizioni. In Miscellanea di studi linguistici in onore di Walter Belardi (vol. 2), eds. P. Cipriano, P. Di Giovine, and M. Mancini, 877–896.. Roma, Italy: Il Calamo.
Gehrke, B. 2008. Ps in Motion: On the Semantics and Syntax of P Elements and Motion Events. Doctoral Dissertation, Utrecht University.
Hagѐge, Claude. 2010. Adpositions. Oxford: Oxford University Press.
Huang, J., A. Li, and Y. Li. 2009. The Syntax of Chinese, Cambridge, Cambridge University Press.
Huang, J. 2009. Lexical decomposition, silent categories, and the localizer phrase. YuyanxueLuncong, 39(1). 86–122.
Kang, Y. 2012. A cognitive linguistics approach to the semantics of spatial relations in Korean. Doctoral Dissertation, Washington Georgetown University, Ph.D.
Kim, J.–B. 2016. The Syntactic Structures of Korean. Cambridge: Cambridge University Press.
Kim, J.–B. and I. Choi. 2004. The Korean Case System: A unified, constraint-based approach. Language Research 40(4). 885–921.
Ko, K. S. 2008. Korean Postpositions as Weak Syntactic Heads. In Proceedings of the 15th International Conference on Head-Driven Phrase Structure Grammar, ed. Müller, Stefan, National Institute of Information and Communications Technology, Keihanna, 131–151. Stanford, CA: CSLI Publications.
Ko, K. S. 2013. Les postpositions du coréen en HPSG. In Prépositions et Postpositions. Approches typologiques et formelles, ed. J. Tseng, 170–195.Toulouse: Editions Lavoisier.
Le Pesant, D. 2011. Problèmes de morphologie, de syntaxe et de classification sémantique dans le domaine des prépositions locatives. In Au Commencement était le Verbe. Syntaxe, Sémantique et Cognition. Mélanges en l’honneur du Professeur Jacques François, ed. F. Neveu, P. Blumenthal and N. Le Querler, 349–371. Berlin : Peter Lang.
Le Pesant, D. 2012. Essai de classification des prépositions de localisation. In Actes du Troisième Congrès Mondial de Linguistique Française, ed. F. Neveu, V. Muni Toke, J. Durand, T. Klingler, S. Prévost and S. Teston-Bonnard, 921–936. Paris: Institute de la langue Française.
Libert, A. 2013. Adpositions and Other Parts of Speech. Barlin: Peter Lang.
Li, C. N., and S. Thompson. 1981. Mandarin Chinese: A Functional Reference Grammar, Berkeley: University of California Press.
Liu, F., 1994. A note on clitics and affixes in Chinese. in J. Camacho, L. Choueiri (eds.), North American Conference of Chinese Linguistics, 6, 137–143.
Liu, F., 1998, A clitic analysis of locative particles. Journal of Chinese Linguistics 26(1). 48–70.
Peyraube, A., 1980, Les constructions locatives en chinois moderne, Paris, Editions 21 Langages croisés.
Peyraube, A., 1994. On the history of Chinese locative prepositions, Zhongguo jingneiyuyan ji yuyanxue, 2. 361–387.
Peyraube, A. 2003. On the history of place words and localizers in Chinese: a cognitive approach, in A. Li, A. Simpson (eds), Functional Structure(s), Form and Interpretation, 180–198. London: Routledge-Curzon.
Real Puigdollers, C. 2013. Lexicalization by Phase: The role of prepositions in argument structure and its cross-linguistic variation. Doctoral Dissertation. Barcelona, Spain: Universitat Autònoma de Barcelona.
Rhee, S. 2004. A comparative analysis of grammaticalization of English and Korean
Adpositions. Studies in Modern Grammar 40(2). 209–233.
Rhee, S. 2008. On the rise and fall of Korean nominalizers. Rethinking grammaticalization: New perspectives, eds López-Couso MJ and E. Seoane, 239–264. Amsterdam: John Benjamins.
Rizzi, L. 1991. Il sintagma preposizionale. In Grande grammatica Italiana di consultazione (vol. 2), eds. Renzi, L. and G. Salvi, 507–531. Bologna, Italy: Il Mulino Editore.
Roy, I.. 2006. Body part nouns in expressions of location in French. Nordlyd 33(1). 98–119.
Son, M.. 2006. Directed Motion and Non-Predicative Path P in Korean. Nordlyd 34(2). 70–95.
Svenonius, P. 2008. Projections of P. In Syntax and Semantics of Spatial P, ed. Anna Asbury, J. Dotlačil, B. Gehrke and R. Nouwen, 63–84. Amsterdam: John Benjamins.
Svenonius, P. 2010. Spatial P in English. In The Cartography of Syntactic Structures, Vol. 6, ed. G. Cinque and L. Rizzi, 127–160. Oxford: Oxford University Press.
Stosic. D. 2007. The Prepositions “par” and “à travers” and the categorization of spatial entities in French. In The Categorization of Spatial Entities in Language and Cognition, ed. M. Aurnague, M. Hickmann and L. Vieu, 71–91. Amsterdam: John Benjamins.
Sun, C., 2006, Chinese: A Linguistic Introduction, Cambridge: Cambridge University Press.
Melis, L. 2003. La Préposition en Français. Paris: Ophrys.
Talmy, L. 2000. Towards a Cognitive Semantics. Cambridge, MA: The MIT Press.
Ursini, F.–A. & J. Baik. 2021. Measure Phrases and Spatial Categories in Korean: The compositional roots of measurement. Wuhan & Seoul: Manuscript.
Ursini, F.–Alessio, H. Long, and Y. Zhang 2020. (Un)bounded categories in
Mandarin. Romanian Review of Linguistics/Revue roumaine de linguistique 65(2). 119
133.
Ursini. F.–A. and Keith Tse. 2021. Region Prepositions: The view from French. Canadian Journal of Linguistics 66(1), 31–59.
Ursini. F.–A. and T. Wu. 2021. On Italian Spatial Prepositions and Measure Phrases: reconciling data with theoretical accounts. Wuhan: Manuscript.
Vandeloise, C. 1986. L’espace en Français: Sémantique des Prépositions Spatiales. Paris: Editions du Seuil.
Vandeloise, C. 1987. La préposition à et le principe d’anticipation. Langue Française 76(1).77–111.
Vandeloise, C. 1988. Les usages spatiaux statiques de la préposition à. Cahiers de Lexicologie 53(1). 119–148.
Vandeloise, C. 1991. Spatial Prepositions: A Case Study in French. Chicago, IL: University of Chicago Press.
Vandeloise, C. 1994. Methodology and Analyses of the Preposition ‘in’. Cognitive Linguistics 5(2). 157–184.
Vandeloise, C. 2003. Langues et Cognition. Paris: Hermes.
Voghera, M. 1994. Lessemi complessi: percorsi di lessicalizzazione a confronto. Lingua e Stile 29(2). 185–214.
Voghera, M. 2004. Polirematiche. In La formazione delle parole in italiano, eds. M. Grossmann and F. Rainer, 56–69. Tübingen, Germany: Max Niemeyer Verlag.
Vieu, L. 1991. Sémantique des Relations Spatiales et Inférences Spatio-Temporelles: Une Contribution à l’étude des Structures Formelles de l’Espace en Langage Naturel. Doctoral Dissertation, IRIT Université Paul Sabatier.
Zhang, N.2017. Adpositions. Encyclopaedia of Chinese Language and Linguistics, eds. R. Sybesma, W. Behr, Y. Gu, Z. Handel, C. Huang and J. Myers, 709–718. Leiden, Brill.
Zwarts, J. 1997. Vectors as relative positions: a compositional semantics of modified PPs. Journal of Semantics 14(1). 57–86.
Zwarts, J., and Y. Winter. 2000. Vector space semantics: A Model–Theoretic analysis of Locative Prepositions. Journal of Logic, Language and Information 9(2). 169–211.
De la notion spatiale d’extérieur à la valeur grammaticale d’exception et de restriction : l’enclitique pakke en coréen et la préposition complexe en dehors de en français
Injoo Choi-Jonin & Véronique Lagae
0. Introduction
En coréen, les fonctions syntaxiques, sémantiques ou pragmatiques peuvent être marquées par des marqueurs fonctionnels, qui correspondent à la catégorie des mots considérée traditionnellement comme josa (‘mot auxiliaire’), en grammaire coréenne. Il s’agit des morphèmes liés, appelés par Sohn Ho-Min (1999 : 213) postpositional function words, étant donné qu’ils suivent un constituant nominal, adverbial ou une proposition ; il reconnaît cependant que certains se comportent comme des suffixes d’un point de vue phonologique. C’est le cas en effet du nominatif, de l’accusatif et du génitif, qui se comportent comme des suffixoïdes, dans le sens où s’ils manifestent des propriétés phonologiques des suffixes, leur présence après la « base » n’est pas obligatoire.
Parmi les autres marqueurs fonctionnels, qui peuvent être analysés comme des enclitiques (cf. Choi-Jonin 2008), certains peuvent être classés dans la catégorie de postpositions, si on s’appuie sur la définition suivante :
– une postposition est un mot relationnel, qui relie le constituant nominal qu’il suit à un autre constituant de l’énoncé ;
– elle détermine le trait sémantique du constituant qu’il suit.
Cette définition se base sur Lemaréchal (1998 : 202-203), pour qui une préposition est non seulement un élément relationnel, mais aussi un élément classifieur, dans le sens où elle classifie son régime comme une entité représentant telle ou telle propriété sémantique.
Les postpositions, définies ainsi, sont généralement simples en coréen, et à notre connaissance, les postpositions complexes, formées avec une base nominale, sont quasi absentes. Parmi les enclitiques nominaux, nous n’avons relevé en fait qu’un cas, formé du nom signifiant ‘extérieur’ et du locatif : pakk-e (‘extérieur’-Loc). Cette forme grammaticalisée, employée comme un enclitique à valeur restrictive ou exceptive, ne fonctionne pourtant pas comme une postposition, telle que nous l’avons définie, dans la mesure où elle ne sélectionne pas le constituant qu’elle suit. Ce qui est néanmoins intéressant à observer dans ce cas est que si on transpose métaphoriquement la relation spatiale à l’emploi grammatical de pakk-e, la position relative des deux entités spatiales, « Site » et « Cible », impliquées par le nom relationnel pakk (‘extérieur’), se trouve inversée dans son emploi lexical et dans son emploi grammatical.
Ce phénomène s’observe également dans le cas de la préposition complexe en dehors de en français, qui peut être employée comme un relateur spatial, comme une préposition de sens exceptif ou restrictif, et comme un connecteur discursif (cf. Borillo 2018), et dans ses trois emplois, le régime de la préposition complexe représente soit le « site », soit la « cible ». L’hypothèse avancée dans cette étude sera alors que ce phénomène d’inversion de la position entre les deux entités impliquées dans la relation spatiale constitue un paramètre de grammaticalisation, paramètre qui n’a pas été mis en avant jusqu’à présent, à notre connaissance.
1.1. Emploi lexical du nom pakk (‘extérieur’) en coréen
Le nom relationnel pakk, qui signifie ‘extérieur’, est un nom syntaxiquement autonome, pouvant être suivi de différents marqueurs fonctionnels :
(1) cip pakk-i sikkeurepta
maison extérieur-Nom être bruyant
Litt : ‘L’extérieur de la maison est bruyant’
(2) cip pakk-e nuka iss-ta
Maison extérieur-Loc1 quelqu’un être-ST
‘Il y a quelqu’un à l’extérieur de la maison’
(3) pakk-ul poa-ra
extérieur-Acc regarder-ST(Imp)
‘Regarde dehors/ l’extérieur’
(4) pakk-eseo nola-ra
extérieur-Loc2 jouer-ST
‘joue dehors/ à l’extérieur’
Dans cet emploi lexical de pakk, le nom employé comme son complément est un nom spatial : dans les exemples (1-2), il est représenté par cip (‘maison’) ; dans les deux autres exemples à l’impératif, son absence indique qu’il correspond au lieu d’énonciation et on a affaire à un cas de déictique zéro. Qu’il soit représenté ou non par un terme lexical, le complément du nom pakk constitue le site, par rapport auquel est localisée la cible. En (2), nuka (‘quelqu’un’) constitue la cible et il est localisé à l’extérieur de la maison, qui constitue donc le site. En (4) où le complément du nom pakk est absent, c’est le lieu d’énonciation qui constitue le site ; dans cet énoncé impératif, c’est l’allocutaire qui constitue la cible, et il est localisé à l’extérieur du site, qui correspond donc au lieu d’énonciation. Cette relation spatiale peut être schématisée comme suit :
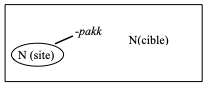
1.2. Emploi grammatical de pakk-e (‘extérieur’-Loc) en coréen
Dans son emploi grammatical, le nom pakk ne peut se combiner qu’avec le marqueur locatif, et la forme pakk-e (‘extérieur’-Loc), accompagnée d’un prédicat négatif, exprime un sens restrictif. Cette forme, employée comme un enclitique nominal, doit obligatoire être précédée d’un nom qui peut être de n’importe quel type, et non uniquement un nom spatial :
(5) naengjanggo-e uyu=pakk-e eop-ta
frigidaire-Loc lait=pakk-e ne.pas.avoir
‘Il n’y a que du lait dans le frigidaire’
(6) naengjanggo=pakk-e mos-sa-ss-ta
frigidaire=pakk-e Nég-acheter-Pas-ST (Décl)
‘(je) n’ai pu acheter que le frigidaire’
Si on transpose métaphoriquement la relation spatiale impliquée par le nom pakk (‘extérieur’) à cet emploi grammatical non-spatial, on remarque que le nom qui précède l’enclitique pakk-e représente une entité à mettre en dehors d’un site ; il ne correspond donc pas au site, contrairement à ce qui se passe dans son emploi lexical. En effet, pour expliquer la valeur restrictive de la forme grammaticalisée pakk-e,employée avec un prédicat négatif, il faut admettre que le support nominal de pakk-e s’inscrit dans un ensemble, et qu’il se présente comme le seul élément sélectionné dans cet ensemble. Le support nominal de pakk-e peut alors être comparé à une cible, localisée à l’extérieur de cet ensemble, comparable donc à un site.
On notera aussi que dans l’emploi spatial, la cible et le site sont représentés par deux constituants syntaxiques différents ; en (2), la cible est représentée par le constituant sujet et le site, par le complément locatif. En revanche, dans l’emploi non-spatial, ce qui peut être pris comme site est le paradigme auquel appartient le constituant en pakke-e à valeur restrictive. En (5), c’est le constituant sujet qui est suivi de l’enclitique restrictif, et il se présente comme le seul élément disponible dans le paradigme du sujet. Avec le prédicat existentiel négatif epta (‘ne pas être/ ne pas se trouver’), qui implique la non-localisation du sujet dans un lieu, cet énoncé peut être interprété ainsi : ‘si on exclut le lait du paradigme du sujet, il n’y a rien qui peut être localisé dans le frigidaire’. En (6), le prédicat n’implique pas de localisation, mais il est possible d’expliquer la valeur restrictive de pakk-e en transposant la relation spatiale du nom pakk (‘extérieur’) à son emploi grammatical, si on accepte notre hypothèse. Dans cet exemple, le constituant objet peut être considéré comme élément-cible à extraire du paradigme-site auquel il appartient. Sa valeur restrictive peut être expliquée par le fait que le paradigme de l’objet du verbe acheter ne contient rien, si le constituant en pakke-e est mis hors de ce paradigme.
Notre hypothèse suggère ainsi un changement du rôle référentiel joué par le nom qui précède pakk, par rapport à son emploi lexical.
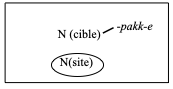
L’enclitique pakk-e peut également être employé avec un sens exceptif ou additif, mais dans ce cas, il est précédé du démonstratif distal keu ou proximal i, à valeur anaphorique:
(7) keu.pakk-e jasehan sahang-eun samusil-lo munui-ha-se-yo
ce.pakk-e détaillé question-Th bureau-Dir demande-faire-Hon-ST
‘En dehors de cela/ en plus de cela, pour des questions plus précises, renseignez-vous auprès du bureau’
Cette forme construite avec un démonstratif ne peut pas être employée pour un sens restrictif. Dans cet emploi aussi, le constituant en pakk-e est présenté hors du paradigme auquel il appartient, mais à la différence de son emploi restrictif, le paradigme dont il est extrait contient d’autres éléments que lui.
2. Emplois de la préposition complexe en dehors de en français
Employée comme relateur spatial, la préposition complexe en dehors de sélectionne comme son régime un nom spatial, qui construit le site, à l’extérieur duquel est localisée la cible :
(8) Comme la cuisine se trouvait en dehors de la maison, dans un bâtiment annexé, … (Maupassant > TLFi)
En dehors de peut aussi exprimer un sens exceptif ou additif, et dans ce cas, son régime n’est plus restreint à des noms spatiaux ; il ne constitue donc plus le site, mais représente une entité à localiser (cible), à l’extérieur d’un cadre (site), qui correspond au paradigme auquel appartient le régime de la locution prépositionnelle. En (9), où en dehors de exprime un sens exceptif, son régime quelques étrangers de passage, tout comme M. Swann, s’inscrit dans le paradigme du sujet de la relative qui vînt chez nous à Combray ; dans cet exemple, il est placé hors de ce paradigme, dans lequel est laissé seulement M. Swann. En (10), où en dehors de exprime un sens additif, son régime est extrait du paradigme de l’objet du verbe il y a, dans lequel figurent encore des centaines d’autres ; son interprétation additive est due au fait que ce qui est mis hors du paradigme n’est pas considéré comme un élément négligeable, et c’est ce qui différencie cet emploi de l’emploi exceptif.
(9) Le monde se bornait habituellement à M. Swann, qui en dehors de quelques étrangers de passage, était à peu près la seule personne qui vînt chez nous à Combray, […]. (Proust > TLFi)
(10) Je savais bien qu’en dehorsdes grosses planètes comme la terre, Jupiter, Mars, Vénus, auxquelles on a donné des noms, il y en a des centaines d’autres […].(Saint-Exupéry > TLFi)
Employé dans un énoncé négatif, en dehors de peut également exprimer un sens restrictif. Dans l’exemple suivant, c’est le paradigme du prédicat qui est exploité, afin de sélectionner seulement le régime de la locution prépositionnelle dans ce paradigme.
(11) Zatopek, par exemple, il courait, mais en dehors de ça, il ne faisait rien du tout. (Web)
En plus de ces trois emplois de en dehors de, Borillo (2018) mentionne l’emploi comme connecteur discursif :
(12) Ce n’est pas possible de gagner un match en faisant autant de fautes au sol. En dehors de ça, j’ai trouvé que les Anglais faisaient un bon match.
Dans cet emploi comme connecteur discursif, le pronom démonstratif qui suit en dehors de représente l’entité à exclure du « site », constitué par le contexte discursif.
3. Conclusion
L’enclitique pakk-e en coréen et la préposition complexe en dehors de en français manifestent en gros les mêmes propriétés. Dans leur emploi comme relateur spatial, le constituant avec lequel ils forment une unité syntaxique constitue le site, alors que dans leur emploi restrictif ou exceptif, il constitue une entité à extraire du paradigme auquel il appartient. En transposant la relation spatiale impliquée par la notion d’extériorité dans le domaine grammatical, nous avons avancé l’hypothèse selon laquelle la position relative des deux entités spatiales, « Site » et « Cible », se trouve inversée dans son emploi lexical et dans son emploi grammatical. Ce changement du rôle de référence spatiale semble donc constituer un paramètre de grammaticalisation, pour l’enclitique en coréen et pour la préposition complexe en français.
Références
Adler, S. (2001), Les locutions prépositives : questions de méthodologie et de définition. Travaux de linguistique, 42-43, 157-170.
Borillo, A. (2018), L’usage des expressions à côté de ça, en face de ça, en dehors de ça, (mis) à part ça …dans une fonction discursive d’orientation argumentative, in P. Blumenthal (éd.), 2018, Études diachroniques du français et perspectives sociétales, Bern, Lang, 47-64
Choi-Jonin, I. (2008), Particles and postpositions in Korean, in D. Kurzon & S. Adler (éds), Adpositions: Pragmatic, semantic and syntactic perspectives,Amsterdam: John Benjamins [Typological Studies in Language 74], 133–170.
Fagard, B. & De Mulder, W. (2007), La formation des prépositions complexes : grammaticalisation ou lexicalisation ? Langue française, 156, 9-29.
Fagard, B. (2012), Prépositions et locutions prépositionnelles : la question du renouvellement grammatical. Travaux de linguistique 64(1), 161–189.
Lemaréchal, A. (1998), Etude de morphologie en f(x,…). Louvain : Editions Peeters.
Sohn, H.-M. (1999), The Korean Language. Cambridge: Cambridge University Press.
The evolution of complex comparative prepositions in Romance languages
Wiltrud Mihatsch
The evolution of complex comparative prepositions in Romance languages
Throughout the history of French, complex constructions of the type ‘Prep det N Prep’ tend to get entrenched and in some cases are formally reduced, so that the noun seems to become a preposition, while it really is the whole construction that takes up a prepositional function and may be formally reduced in the course of grammaticalization.
Fagard (2020) mentions the following cases:
- du côté de > du côté > côté,
- dans la direction de > dans la direction > direction
- à côté de > à côté
- en face de > en face
Further cases are genre, style, type, niveau (Fagard 2020). Genre, style and type adopt readings corresponding to the simplex preposition comme employed in similative comparisons (see Haspelmath/Buchholz 1998), but in some cases, notably in the case of genre, further develop adverbial and discourse marker uses (Chauveau-Thoumelin 2020, Isambert 2016).
The construction X du genre de Y (Mihatsch in press) went through a process of grammaticalization leading to prepositional uses as a comparison marker and subsequent pragmaticalization processes. So far, the focus in studies of French genre has been on the various pragmaticalized discourse functions in contemporary colloquial French, not on the source construction. The aim of this presentation is to analyse in greater detail the prepositional uses deriving from the construction X du genre de Y (“X of the same type as Y”) and parallel cases of similar nouns in French, Spanish and other Romance languages.
The functional change started out with a construction used for construing superordinate categories:
1. Du haut de l’escarpement qui offre cette vue, on descend dans le précipice par un chemin du genre de celui deKander-Steg, et que l’on a fort bien nommé les galleries; c’est un long zig zag taillé dans le roc perpendiculaire.(FRANTEXT, Ramond de Carbonnières, Louis (1781): Lettres de M. William Coxe à M. W. Melmoth sur l’état politique, civil et naturel de la Suisse)
The complex expression is then grammaticalized as a comparative preposition via a conceptual short-cut leading from the creation of an implicit superordinate to a cognitively simpler comparative use and is then a rough equivalent of comme‘like’:
2. je comprends, dit-il enfin ; c’est pour un roman historique, genre Dumas. (FRANTEXT, Nerval, Gérard de (1854):Les Filles du feu)
The source construction became established in the 19th century in the case of French genre (Mihatsch in press), probably in written and rather technical texts and was adopted in everyday language before it acquired different pragmatic functions. The first uses show the full construction X du/dans le genre de Y. In the course of grammaticalization both prepositions became eliminated, genre may now directly link two elements and functions as a preposition itself (see Danon-Boileau/Morel 1997: 194-195). Today, the reduced variant is by far the most frequent, at least in colloquial language (Chauveau-Thoumelin 2020).
First uses link two noun phrases, however, there are now prepositional uses following and modifying a verb phrase as in 3), along the adverbial hedging use in 4):
3. Pour le reste le beau fixe, un divorce qui s’étire genre guerre de tranchée, mais tout va au mieux dans le meilleur des mondes. (FrTenTen12, Superforum)
4. on était nombreux et on avait genre des horaires ou des tickets pour jouer, c’était toujours douloureux (…) (FrTenTen12, white.wind.free.fr)
A similar timeline can be observed for Spanish and Italian tipo with first attestations of a prepositional use appearing in the 19th century, soon afterwards the first occurrences developed reduced forms (Mihatsch 2020, Voghera 2013):
5. En Extremadura el concejo colectivista del tipo de Sayago debe ser muy frecuente, o quedar importantes restos de él […] (CDH, Costa, J. (1898): Colectivismo agrario en España, Madrid)
‚In Extremadura, the collectivist council of the Sayago type must be very frequent, or remain important rests of it.‘
6. solamente sería posible una dialéctica demoledora y negativa, una dialéctica invertida, más o menos tipoHeidegger. (CDH, García Bacca, J. D. (1940-1942): Invitación a filosofar, España)
‘there would be possible only a damaging and negative dialectics, an inverted dialectics, more or less like Heidegger‘
7. […] un’ora prima di sera, una carrozza di tipo campagnuolo, a due cavalli, si arrestò davanti alla fabbrica del signor Melchisedecco Pardi. (Dia – E. De Marchi, Demettrio Pianelli, 1890)
‘[…] an hour before dark, a coach of the country type, with two horses, stopped in front of Mister Melchisedecco Pardi’s factory’
8. Appositi tabelloni avvisano la vendita del caffè espresso, tipo Africa Orientale […]. (Dia – Il Giornale di Sicilia, 1937)
‘Billboards advertise the sale of espresso, of the type of Africa Orientale’
This phenomenon exists with a very similar absolute and relative chronology in other Romance languages, Norwegian and Swedish (Røste Odden 2019, Rosenkvist/Skärlund 2013) and Russian and other Slavic languages (Kisiel/Kolyaseva to appear), not, however, in German and English.
In my talk, I will focus on incipient and emerging and (at least originally) complex similative prepositions. Based on a corpus analysis (CDH, FRANTEXT) and following the comparative approach of Stosic/Fagard (2019), I will compare the emerging similative prepositions in French and Spanish, which I will complement by a questionnaire-based pilote study and previous analyses of the equivalent constructions in several other Romance languages, namely Catalan, Italian, Portuguese, Romanian, Rumantsch and Sardinian.
In my comparative Romance corpus study I will in particular investigate the following aspects:
- The selection of nouns appearing in a construction that can be reanalysed as a similative preposition
- Semantic characteristics of the emerging preposition
- The formal variants showing different prepositions (as in du genre de/dans le genre de)
- The chronology of appearance of the full and possibly reduced variants
- The possible origins in particular discourse traditions and/or particular domains
I will close with reflections concerning the very similar timeline and selection of nouns cross-linguistically, focussing on possible language contacts and/or common communicative tendencies in Europe triggering the evolution of these complex prepositions.
References
CDH = Instituto de Investigación Rafael Lapesa de la Real Academia Española (2013). Corpus del Nuevo Diccionario Histórico del Español (CDH) (http://web.frl.es/CNDHE/view/inicioExterno.view).
Chauveau-Thoumelin, Pierre (2020): Une approche constructionnelle des enclosures genre et espèce. PhD-thesis, Lille 3.
Danon-Boileau, L. / Morel, M.-A. (1997): « Question, point de vue, genre, style…: les noms prépositionnels en français contemporain ». Faits de Langues, 9, 193-200.
Fagard, B. (2020): „Chapter 32.1 Prépositions et locutions prépositives“, in: C. Marchello-Nizia, B. Combettes, S. Prévost and T. Scheer (eds.): Grande Grammaire Historique du Français (GGHF), Berlin: De Gruyter Mouton, 856- 886.
FRANTEXT = Base textuelle FRANTEXT (https://www.frantext.fr/)
FrTenTen12 = French Web corpus 2012 (https://www.sketchengine.eu/frtenten-french-corpus/)
Isambert, P. (2016): « Genre: une mode récente mais qui vient de loin », Journal of French Language Studies, 26, 85–96.
Kisiel, A. / A. Kolyaseva (to appear): „Towards a comprehensive typology of type noun constructions in Slavic languages, with focus on Polish and Russian“, in Brems, L., Davidse, K., Mihatsch, W., Hennecke, I., Kisiel, A. and Kolyaseva, A. (eds.): Type Noun Constructions in Slavic, Germanic and Romance Languages – Semantics and pragmatics on the move. De Gruyter (https://www.degruyter.com/document/isbn/9783110701166/html)
Mihatsch, W. (2020): « Los orígenes discursivos de los atenuadores procedimentalizados ‘tipo’, ‘onda’, ‘corte’ y ‘rollo’: Una exploración microdiacrónica », Revista Signos 53(104) 686-717.
Mihatsch, W. (in press): “French type-noun constructions based on genre: From the creation of ad hoc categories to ad hoc categorization”, in C. Mauri, I. Fiorentini & E. Goria (Eds.), Building categories in interaction: Linguistic resources at work. New York/Amsterdam: John Benjamins.
Rosenkvist, H. / Skärlund, S. (2013): “Grammaticalization in the present – the changes of modern Swedish typ”, in A. Giacalone Ramat, C. Mauri & P. Molinelli (eds.): Synchrony and Diachrony: A dynamic interface. Amsterdam: John Benjamins (Studies in Language Companion Series 133), 313–338.
Røste Odden, O. (2019): North Scandinavian type noun constructions: Patterns with slags, SORTs and TYP(E). PhD-thesis, University of Oslo (available at: https://www.academia.edu/44408143/North_Scandinavian_type_noun_constructions_Patterns_with_slags_SORTs_and_TYP_E_).
Stosic, D. / Fagard, B. (2019): „Les prépositions complexes en français : pour une méthode d’identification multicritère“. Revue Romane, 54 (1), 8-38.
Voghera, M. (2013): “A case study on the relationship between grammatical change and synchronic variation: The emergence of tipo[-N] in Italian”. In A. Giacalone Ramat, C. Mauri & P. Molinelli (Eds.): Synchrony and Diachrony. A dynamic interface. Amsterdam: John Benjamins, 283-312.
En présence d’une profusion de formes : productivité en diachronie du paradigme prépositionnel en N de
Quentin Feltgen
Les prépositions complexes sont fréquemment le résultat d’un processus de lexicalisation et/ou de grammaticalisation (Fagard & De Mulder, 2007), à savoir qu’elles se trouvent intégrées dans le lexique des locuteurs en étant forgées dans des contextes spécifiques à partir de contenus linguistiques plutôt conceptuels (principalement, le nom commun autour duquel elles s’articulent) pour endosser une fonction plutôt procédurale, ici une fonction prépositionnelle. Cependant, ainsi que l’a fait remarquer Hoffmann (2004, 2007) dans le cas de l’anglais, toutes les prépositions complexes ne semblent pas dériver d’un processus de grammaticalisation. En effet, les prépositions complexes sont caractérisées par une profusion étonnante, et nombre d’entre elles restent trop marginales et peu fréquentes pour qu’on puisse les comprendre comme le résultat d’un processus diachronique où la fréquence constitue un facteur décisif pour opérer la réanalyse des contenus conceptuels en un tout unifié et procédural (Bybee 2006).
La profusion des prépositions complexes met ainsi en lumière un possible processus de constructionnalisation à un niveau plus schématique (Trousdale 2014). Nous adopterons en effet l’hypothèse – déjà soutenue pour sous DN (Lauwers 2010) -, que l’inscription dans le lexique des locuteurs d’une construction plus abstraite permet de donner sens à la multiplicité des formes rencontrées, celles-ci étant alors comprises comme des instanciations de ce schéma, diversement établies dans l’usage, que la coercion sémantique exercée par la construction permet de doter d’un sens prépositionnel (Lauwers & Willems 2010). L’exemple que nous avons choisi ici, le paradigme prépositionnel en N de, peut être ainsi utilement compris comme un schéma cognitivement intégré au lexique des locuteurs, comprenant une importante variété d’instanciations possibles, tels en fonction de (Pichal 1971) ou en voie de (De Mulder 2019), qu’il est possible d’enrichir de nouveaux membres, ceux-ci se trouvant alors établis comme prépositions complexes sans nécessairement passer par un processus de grammaticalisation, notamment grâce au mécanisme d’analogie (Traugott 2008, Fischer 2018).
Cette lecture constructionnelle suscite en corollaire des questions nouvelles. En particulier, le mécanisme d’analogie devrait élargir le paradigme établi à un nombre sans cesse croissant de formes, chacune en appelant chaque fois de nouvelles auxquelles elle se trouve liées par rapprochement analogique, ce que contredisent les observations empiriques, d’où il ressort que la productivité d’un paradigme reste limitée. On peut alors postuler, d’une part, l’existence d’une organisation interne qui limiterait l’apparition de nouveaux membres, en les confinant à la marge d’une structure en « loi de Zipf », observée pour certaines constructions (Perek & Lemmens 2010, Ellis 2012, Ellis et al. 2014) ; d’autre part, qu’il existe au sein du paradigme un phénomène de renouvellement sémantique et de compétition entre les formes, qui compense le recrutement de nouveaux membres par l’éviction d’autres précédemment établis.
Dans cette étude, nous mettons en évidence ces deux composantes structurelles, à partir d’un exemple choisi pour sa richesse autant que pour sa complexité, le paradigme de prépositions de la forme en N de. Ce paradigme est attesté dès l’époque médiévale, avec par exemple en maniere de et en lieu de (Fagard 2009), époque à laquelle en servait de préposition locative principale. Nous nous limiterons néanmoins à la période postérieure à 1701, qui marque un aboutissement dans le long processus de remplacement des fonctions locatives de en par dans (Fagard & Combettes 2013). Il s’agit donc d’une période où le paradigme est déjà établi ; nombre de représentants emblématiques du schéma, comme en mémoire de ou en vue de, sont ainsi déjà parfaitement intégrés dans l’usage de la langue.
Notre étude se décompose en deux volets. Le premier, qualitatif, vise à présenter la diversité des formes rencontrées dans le paradigme et à discuter des limites de son interprétation en termes de schéma constructionnel ; le second, quantitatif, donne un aperçu des tendances dynamiques et des contraintes structurelles qui sous-tendent l’évolution du paradigme. Ces deux volets s’appuient sur les données textuelles du corpus Frantext (2021), où nous avons relevé, au terme d’une sélection manuelle pour écarter les formes ne donnant pas lieu à des emplois prépositionnels, près de 300 formes distinctes sur la période considérée (1701-2000), nous restreignant aux emplois sans article accompagnant le nom (voir Smith (2013) pour une discussion sur ce point dans le cas de l’anglais). Les fréquences de ces formes ont ensuite été extraites pour chacune des six périodes de 50 ans couvertes par la sélection.
La préposition en n’étant plus la préposition locative privilégiée à partir du XVIIIème siècle, on peut supposer que la réanalyse ne permet guère d’expliquer les formes intégrées au paradigme après cette date. La préposition participe néanmoins d’un vaste éventail de constructions (De Mulder & Amiot 2013), qui restent productives et peuvent donner lieu à des prépositions nouvelles. Il existe par exemple une gradation entres des formes entièrement lexicalisées et des formes qui tendent à assurer une fonction prépositionnelle (en robe de chambre > en habit de marin > en façon de bravade), ce qu’illustre également la grammaticalisation de en guise de. Ceci suggère un rapport pluriel entre analogie et réanalyse : l’analogie peut ainsi permettre de recruter des nouveaux membres dans les schémas lexicaux, qu’une réanalyse en contexte peut ensuite individuellement distinguer et enrichir d’usages prépositionnels, notamment par analogie ou contamination constructionnelle (Pijpops et al. 2018) avec des prépositions existantes du même type. On observe cependant des cas manifestes d’analogie directement au niveau prépositionnel lui-même ; sur le modèle de prépositions relativement fréquentes comme en récompense de, on trouvera notamment en nantissement de ou encore en défalcation de ; de même, le vingtième siècle voit l’apparition de nombreuses prépositions spatiales comme en exergue de, qu’accompagnent dans leur sillage des prépositions plus occasionnelles (en couverture de, en frontispice de).
Le tableau qui émerge de ces observations est celui d’un schéma présentant un éclatement de sous- ensembles disparates, avec des significations souvent éloignées (ex. en raison de et en arrière de). Cette diversité sémantique ne plaide pas en faveur d’une lecture constructionnelle du paradigme, qui supposerait un sens partagé au travers de ces différents groupements. Plus qu’une construction organisée autour d’un noyau de membres prototypiques participant d’une communauté sémantique et de membres plus marginaux pouvant s’en éloigner, il semblerait que l’on ait affaire ici à une constellation de prototypes réunissant chacun un petit ensemble de formes sémantiquement liées, et ne partageant entre eux qu’une analogie lâche de forme pouvant très bien être le résultat d’un état de fait n’émergeant qu’a posteriori de leurs évolutions respectives.
Le second volet de l’étude suggère qu’il est malgré tout pertinent de considérer le paradigme en N de comme un « locus » linguistique présentant une certaine cohérence. Tout d’abord, les arguments les plus représentés ne recoupent que partiellement les préférences distributionnelles de en (Vigier 2017). En outre, pour cinq des six périodes considérées, l’ensemble des membres obéit à une loi de Zipf entre fréquence et rang, loi dont le coefficient reste stable, indice d’une cohérence organisationnelle compatible avec une lecture constructionnelle. En revanche, la dernière tranche (1951-2000) dévie fortement de cette organisation, d’une manière concomitante à l’apparition rapide de nouveaux termes au sémantisme essentiellement spatial et temporel (en amont de, en début de, en bord de, etc.). En considérant les 20 formes les plus fréquentes pour chacune des six périodes de 50 ans étudiées ici, il apparaît que l’émergence de ces formes spatiales se traduit également par une tombée en désuétude d’autres formes (comme en état de ou en comparaison de), indiquant un réalignement sémantique du paradigme.
En combinant des aspects quantitatifs et qualitatifs, notre étude explore ainsi la complexité de l’organisation en diachronie d’un riche paradigme de prépositions complexes, les locutions prépositives obéissant au schéma en N de. Si elle ne permet pas de répondre de manière définitive aux questions théoriques relatives au statut constructionnel de ce schéma et aux mécanismes qui permettent de l’enrichir, elle apporte de nouveaux éléments clefs à la réflexion, en particulier en considérant les dynamiques du rang de fréquence à travers les différentes périodes considérées, et en exploitant la loi de Zipf pour rendre compte de l’organisation structurelle de cette multiplicité déroutante de prépositions hétérogènes.
Bibliographie
Bybee, J. (2006). From usage to grammar: The mind’s response to repetition. Language, 711-733.
De Mulder, W. (2019). En voie de: Du trajet spatial à l’aspect. Revue Romane. Langue et littérature. International Journal of Romance Languages and Literatures, 54(1), 39-61.
De Mulder, W., & Amiot, D. (2013). En: de la préposition à la construction. Langue française, (2), 21-39.
Ellis, N. C. (2012). Formulaic language and second language acquisition: Zipf and the phrasal teddy bear. Annual review of applied linguistics, 32, 17.
Ellis, N. C., O’Donnell, M., & Römer, U. (2014). Does language Zipf right along? Investigating robustness in the latent structures of usage and acquisition. In Connor-Linton J. Amoroso L.W. (éds), Measured Language: Quantitative Studies of Acquisition, Assessment, and Variation, Georgetown University Press, 33-50.
Fagard, B. (2009). Prépositions et locutions prépositionnelles: un sémantisme comparable?. Langages, (1), 95-113.
Fagard, B., & Combettes, B. (2013). De en à dans, un simple remplacement? Une étude diachronique. Langue française, (2), 93-115.
Fagard, B., & De Mulder, W. (2007). La formation des prépositions complexes: grammaticalisation ou lexicalisation?. Langue française, (4), 9-29.
Fischer, O. (2018). Analogy: Its role in language learning, categorization, and in models of language change such as grammaticalization and constructionalization. In Hancil, S., Breban, T., Lozano, J. V., New Trends in Grammaticalization and Language Change, John Benjamins Publishing Company, 75-104.
Frantext (2021). Base textuelle Frantext, ATILF (CNRS) & Université de Lorraine. http://www.frantext.fr
Hoffmann, S. (2004). Are low-frequency complex prepositions grammaticalized. Corpus approaches to grammaticalization in English, 171-210.
Hoffmann, S. (2007). Grammaticalization and English complex prepositions: A corpus-based study. Routledge.
Lauwers, P. (2010). Les locutions en sous comme constructions. Français Moderne, 78(1), 3-27.
Lauwers, P., & Willems, D. (2011). Coercion: Definition and challenges, current approaches, and new trends. Linguistics, 49(6), 1219-1235.
Perek, F., & Lemmens, M. (2010). Getting at the meaning of the English at-construction: the case of a constructional split. CogniTextes. Revue de l’Association française de linguistique cognitive, (Volume 5).
Pichal, W. (1971). Un exemple d’imprécision lexicale: en fonction de. Equivalences, 2(1), 10-22. Pijpops, D., De Smet, I., & Van de Velde, F. (2018). Constructional contamination in morphology and syntax: four case studies. Constructions and Frames, 10(2), 269-305.
Smith, A. (2013). Complex prepositions and variation within the PNP construction. In Hasselgård, H., Ebeling K., Oksefjell Ebeling S. (éds), Corpus Perspectives on Patterns of Lexis, John Benjamin, 153-174.
Traugott, E. C. (2008). The grammaticalization of NP of NP patterns. Constructions and language change, 23-45.
Trousdale, G. (2014). On the relationship between grammaticalization and constructionalization. Folia Linguistica, 48(2), 557-578.
Vigier, D. (2017). L’évolution des usages des prépositions en, dans, dedans entre le XVIe et le XXe siècle: approche distributionnelle sur corpus outillé. Discours. Revue de linguistique, psycholinguistique et informatique. A journal of linguistics, psycholinguistics and computational linguistics, (21).
Diachrony and synchrony of multiword prepositional phrases in (some) Romance languages. A corpus-based analysis
Valentina Piunno & Vittorio Ganfi
The traditional idea that the lexicon was an inventory of idiosyncratic and irregular entities has been questioned by several theoretical frameworks. Various approaches have shown the existence of regular schemas beyond the lexicon (cf. at least, Bybee 2006, 2011; Hopper & Traugott 2003). This work is aimed at analysing the domain of complex prepositions, through the description of synchronic and diachronic features of such structures. In particular, it intends to investigate the dynamics of lexicalisation and grammaticalisation that led to the formation of multiword prepositional phrases in some contemporary Romance languages (i.e. Italian, French, Spanish), starting from the analysis of the configurations in their oldest phases.
Among the set of complex lexemes, those appearing as prepositional phrases are heterogeneous in both structural and functional terms (Giacalone Ramat 1994; Fagard & De Mulder 2007; Leeman 2007; Ganfi & Piunno 2017; Piunno & Ganfi 2019; 2021; Fagard, Pinto de Lima, Stosic & Smirnova 2020). Already in the earliest phases of the three languages taken into account, multiword prepositional phrases with adverbial (1), adjectival (2), prepositional (3) and conjunctional (4) functions are attested.
(1) Adverbial PPs
a. Old Italian: perdè l’avere […] in ciocca
‘he completely lost his property’ (lit. he lost the property in a lock of hair)
(A. Pucci, Centiloquio, a. 1388 (fior.), c. 9, terz. 42, vol. 1, p. 103).
b. Old Spanish: vendimiar a medias
‘to harvest in half’ (lit. to harvest at half)
(Anónimo, Libro de los fueros de Castiella, 1284).
c. Middle French: (il) fut abatu de plaine arrivée
‘(he) was quickly knocked over’
(Doc. Poitou G., t.9, 1449, 117).
(2) Adjectival PPs
a. Old Italian: gambe a gangheri
‘well-articulated legs’ (lit. legs at head metal)
(Sacchetti, Trecentonovelle, XIV sm. (fior.), 178, p. 445.34).
b. Old Spanish: rey de buen entendimiento
‘intelligent king’ (lit. king of goof skills)
(Alfonso X, General Estoria, II parte, 1275)
c. Middle French: chevalier […] de grant part
‘knight of noble origins’ (lit. knight of big part)
(CHASTELL., Chron. K., t.2, c.1456-1471, 193).
(3) Prepositional PPs:
a. Old Italian: d’arrassu de la sua gructa
‘far from the cave’
(Giovanni Campulu, 3, 16, 1315).
b. Old Spanish: por parte de su padre era de alto linaje
‘from the side of his father (he) was of high lineage’
(Anónimo, Crónica de Don Álvaro de Luna, c1453).
c. Middle French: à la requeste de Colin Le Rotisseur
‘upon the request of Colin Le Rotisseur’
(Reg. crim. Chât., I, 1389-1392, 205).
(4) Conjunctional PP:
a. Old Italian: al te[m]po che andò nel’oste
‘when he went to the innkeeper’
(Documento pistoiese, 1,60, 1240-50).
b. Old Spanish: en tal manera que nos […] damos a uos toda quanta heredat ‘in a manner that we give you all the heritage’
(Anónimo, Carta de cambio, c1218-1300).
c. Middle French: en telle façon que, […], tout fut bruslé ‘in a certain manner that all was burnt’
(ROYE, Chron. scand., I, 1460-1483, 267).
In the contemporary stages of the Romance languages considered, several uses of multiword prepositional phrases with adverbial (5), adjectival (6), prepositional (7) and conjunctional (8) functions can be considered, in terms of frequency of use and types of configurations.
(5) Adverbial PPs
a. Contemporary Italian: ha parlato a briglia sciolta
‘he spoke at full gallop’ (lit. he spoke at loose bridle)
b. Contemporary Spanish: trabajar por comisión
‘work on order’ (lit. to work for commission)
c. Contemporary French: le petit train avance à toute allure
‘the small train moves forward very fast’ (lit. the small train moves forward at all speed)
(6) Adjectival PPs
a. Contemporary Italian: occhiali a goccia
‘drop-shaped glasses’ (lit. glasses at drop)
b. Contemporary Spanish: tela de rayas
‘pinstripe’ (lit. tissue at rows)
c. Contemporary French: voitures en circulation
‘moving cars’ (lit. cars in circulation)
(7) Prepositional PPs
a. Contemporary Italian: la lettera da parte di un cliente
‘the letter of a customer’ (lit. the letter from part of a customer)
b. Contemporary Spanish: en frente de la casa
‘in front of the house’
c. Contemporary French: au regard de ces considérations…
‘in light of such considerations’
(8) Conjunctional PPs
a. Contemporary Italian: dal momento che stai utilizzando un browser ‘since you are using a browser’ (lit. from the moment that you are using a browser)
b. Contemporary Spanish: de manera que una persona pueda ‘so that a person may’ (lit. of manner that a person may’)
c. Contemporary French: au cas où ils maintiennent leur position ‘in case they keep their position’
This investigation aims at (a) providing a representative frame of the use of the various configurations in the different phases of the languages, (b) clarifying the diachronic relationship between sequences employing the same lexemes in both the Old and Contemporary phases, (c) highlighting the divergences of the complex lexemes’ system in the different phases of the languages. For this purpose, data will be collected through diachronic dictionaries or databases (i.e. the OVIcorpus[1] and the TLIO dictionary[2] for Old Italian, the CORDE[3] corpus for Old Spanish, and the Dictionnaire du Moyen Français[4] for Middle French) and synchronic corpora (i.e. the ITTenTen16[5] for Contemporary Italian, the ESTenTen18[6] for Contemporary Spanish, and the FRTenTen17[7] for Contemporary French).
Multiword prepositional phrases will be distinguished according to their structure (e.g. syntagmatic configuration, type of preposition and lexemes used) and their function (i.e. adverbial, adjectival, prepositional, conjunctional). Each function will be described according to the distributional properties emerging from the analysis of the contexts of use attested in the corpora. Furthermore, the analysis of multiword prepositional phrases will take into consideration the relation between the fixedness and cohesion of the constituents of the prepositional phrases with their degree of grammaticalisation and their frequency of use.
Finally, the historical evolution of the different functions will be considered in order to prove the existence of a historical path that has led to the functional diversification of the system of multiword prepositional phrases in the three Romance languages considered.
References
Bybee, J. (2006). “From Usage to Grammar: The Mind’s Response to Repetition”, Language, 82, 4: 711-733.
Bybee, J. (2011). “Usage-based Theory and Grammaticalization”, in Narrog, H. & Heine, B. (eds.), The Oxford Handbook of Grammaticalization, Oxford: Oxford University Press: 69-78.
Fagard, B. & De Mulder, W. (2007). “La formation des prépositions complexes: grammaticalisation ou lexicalisation?”, Langue française: 156: 9-29.
Fagard, B., Pinto de Lima, J., Stosic, D. & Smirnova, E. (2020). Complex adpositions in European Languages. Berlin: De Gruyter.
Ganfi, V & Piunno, V. (2017). “Preposizioni complesse in italiano antico e contemporaneo. Grammaticalizzazione, schematismo e produttività”, Archivio Glottologico Italiano, CII (2): 184-204.
Giacalone Ramat, A. (1994). “Fonti di grammaticalizzazione. Sulla ricategorizzazione di verbi e nomi come preposizioni”, in Cipriano, P., Di Giovine, P. & Mancini, M. (eds.), Miscellanea di studi linguistici in onore di Walter Belardi. Roma: Il Calamo: 877-896.
Hopper, P.J. & Traugott, E.C. (2003). Grammaticalization. Cambridge: Cambridge University Press.
Leeman, D. (2007). “De la préposition à la locution prépositionnelle”, Modèles linguistique, 55: 7-15.
Piunno, V. & Ganfi, V. (2019). “Usage-based account of Italian Complex Prepositions denoting the Agent”, Revue Romane, 54(1): 141-175.
Piunno, V. & Ganfi, V. (2021). “Synchronic and diachronic analysis of prepositional multiword modifiers across Romance languages”, Lingvisticae Investigationes, 43 (2): 352-379.
Stosic, D. & Fagard, B. (2019). “Les prépositions complexes en français: pour une méthode d’identification multicritère”, Revue Romane, 54 (1): 8-38.
[1] Website: http://gattoweb.ovi.cnr.it/(S(lm2bisijhy1jzpvqqcugebxt))/CatForm01.aspx.
[2] Website: http://tlio.ovi.cnr.it/TLIO/.
[3] Website: http://corpus.rae.es/cordenet.html.
[4] Website: http://www.atilf.fr/dmf.
[5] Website: https://www.sketchengine.eu/ittenten-italian-corpus/.
[6] Website: https://www.sketchengine.eu/esTenTen-spanish-corpus/.
[7] Website: https://www.sketchengine.eu/frtenten-french-corpus/.
Using BERT to Explore Semantic Shifts of Complex Prepositions
Liudmila Radchankava & Vasily Konovalov
The present study aims to investigate some possible ways to semi-automatically detect diachronic functional-contextual changes. In this sense, the aim of this study is to expand the application of embedding-based methods beyond the area of lexical semantics and to further expand the burgeoning research whether contextualized embeddings can be used to study the semantic shifts of complex prepositions.
Key words: BERT, complex prepositions, clustering, semantic shifts
The formation of a new complex preposition is assumed to go along with semantic change of the original construction. The defining characteristic of synsemantic words (prepositions, conjunctions and particles) is the categorical meaning of relativity. Therefore, the most important prerequisite for the transition from autosemantic to synsemantic units is the development of the element of relativity. It is widely accepted that relational meanings in terms of content cannot be concrete and always reflect something abstract. The emergence of a new preposition is influenced by different types of contexts in diachronic development. While a PP develops into a complex preposition, it is expected to become more abstract and therefore polysemous (Lehmann & Stolz:1992: 29).
It is therefore typical that the development of the relativity element in autosemantic words takes place under conditions which are unusual for any given autosemantic unit regarding its syntactic and semantic relations. The development of relativity prevents the semantic correlation to the etymon from being completely lost. Furthermore, the transition from autosemantic units to prepositions leads to the formation of homonyms of a certain type:
- However, such overlapping could be acceptable in view of the importance of recognizing the needs of these groups. (COHA)
- the coronation itself takes place on the balcony of Saint Peter’s Basilica, in view of the crowds assembled in Saint Peter’s Square below. (COHA)
The formation of a new complex preposition assumably coincides with the semantic change of the original construction. As soon as a complex formation is used as an adposition, the direct communication effect of the original metaphor has disappeared (Haspelmath 1999: 1060-61). To the extent that the particular meaning of a basic noun diminishes, new formations with a semantically more substantial core noun appear and correspond exactly to the model in their type of formation (Lehmann 2002: 12). However, in certain sequences, it is difficult to assess whether desemantization has taken place since the core noun of the prepositional addition often has abstract semantics. In this case, a transition from concrete, specific semantics to a more abstract diffuse meaning either does not take place or is difficult to determine.
According to Heine (2002: 86), the diachronic development can be divided into four stages. Level I refers to the « normal » compositional meaning. In stage II there is a bridging context, where the relevant lexical units appear in contexts in which they were not previously used. Furthermore, the newly created contexts can come to the foreground. In stage III a new context is allowed, which dismisses/excludes the original interpretation/meaning. Lastly, the complete target meaning is formed, which is no longer linked to the original meaning and can now be used in new contexts(i.e. conventionalization level IV).
Nonetheless, some prepositions are borrowed and do not undergo all the stages of preposition formation. Presumably, the English preposition by virtue of was probably borrowed from French. Old French had the structurally similar expression par la vertu de, which, according to the Dictionaire historique de la langue française, was documented as early as the 13th century (Hoffmann 2005: 71). We can also find an example of borrowing a preposition from French in Russian. During the formation of the Russian preposition v kačestve, the influence of French (fr. en qualité de) is undisputed. The first indication of its prepositional use can be traced back to the French-Russian translations, and diplomatic correspondence in the 18th century. The preposition v kačestve has the same meanings that are inherent in the French la qualité (‘property’ in the sense of ‘title, position, status’)(cf. Čerkasova 1967: 174).
We introduce a usage-based approach to lexical semantic change analysis which relies on contextualized representations of words. First, given preposition of interest, we label the modern use cases into the number of semantic classes. Then we use BERT language model (Devlin et. al 2019) to compute usage representations for each occurrence of these words. Then we train the model given the contextualized preposition representation and corresponding semantic classes. Having trained the model we classify all the given preposition use cases along the temporal axis. Then we detect and analyze the usage types that were different from the modern usage types. In our second experiment, we assign a label probability distribution to the complex preposition over time. Then we calculate the Kullback–Leibler distance between these distributions and uniform distribution and calculate the correlation between these distances and the year of usage.
Compared to other prepositions, borrowed prepositions initially function as standard prepositions and do not partake in gradual semantic and structural development. With this in mind, there are no measurable diachronic semantic differences expected in these prepositions. As stated earlier, under normal circumstances а new preposition would have required context-induced reinterpretation.
This study shows that BERT embeddings can be used successfully to identify the various functions or usage types of semi-grammatical construction. BERT formulates expected functional-semantic developments from investigated prepositions based on linguistic literature and evaluates whether BERT embeddings can be used in combination with time-sensitive measures automatically recognizes these changes on the examples from the Corpus of Historical American English [COHA] and Russian National Corpus.
References:
Čerkasova, Evdokija Trofimovna. 1967. Perexod polnoznačnyx slov v predlogi. Nauka.
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
Haspelmath, M. 1999. Why is grammaticalization irreversible?. Linguistics, 37(6), 1043-1068.
Heine, Bernd. 2002. On the role of context in grammaticalization. In Wischer, Ilse and Diewald, Gabriele (eds.) :New reflects on grammaticalization. Publisher: John Benjamins Publishing., 83-101
Hoffmann, Sebastian 2005. Grammaticalization and English Complex Prepositions . London.
Lehmann, C. (2002): New reflections on grammaticalization and lexicalization. In: Wischer, I., Diewald, G. (eds.): New reflections on grammaticalization. Amsterdam, Philadelphia: Benjamins, 1-18.
Lehmann, Christian & Christel Stolz. 1992. Bildung von Adpositionen im Deutschen. Erfurt: Seminar für Sprachwissenschaft der Universität (ASSidUE 6).
Russian National Corpus http://www.ruscorpora.ru/
Corpus of Historical American English
Le traitement lexicographique des locutions prépositives françaises dans les dictionnaires français-polonais
Witold Ucherek
Plusieurs auteurs soulignent le caractère ouvert de la classe des locutions prépositives et le grand nombre des unités qui la composent. Ainsi, Novikova (1966) parle d’une bonne centaine de locutions prépositives qui sont déjà entrées dans le système de la langue française et d’environ 450 constructions analytiques fonctionnant comme prépositions dans le texte. À la même époque, Delaunoy (1967) fournit une liste de plus de 320 constructions qu’il considère comme des locutions prépositives. Pougeoise (1996) estime que le nombre de ces locutions atteint 500. Selon Borillo (1997), le nombre des seules locutions prépositives spatiales et temporelles est supérieur à 300. Gross (1981) avance le chiffre d’un millier de constructions contenant un nom classifieur et apparentées aux prépositions, mais il doute que l’on puisse parler d’un tel nombre de locutions prépositives. Or, la nomenclature du dictionnaire français-polonais des prépositions (E. Ucherek 1997) renferme près de mille unités polylexicales.
Ces divergences entre les chercheurs sont dues à ce qu’ils adoptent différentes méthodes d’identification des locutions prépositives. En effet, en vue de décider de l’appartenance d’un groupe de mots à la classe des prépositions composées, ils utilisent des critères de nature très variée : les critères sémantique, syntaxique, distributionnel, flexionnel (opératoire notamment pour les langues slaves), fréquentiel et même technique (test de traduction en langue étrangère). Dans la majorité des cas les tests qu’ils proposent ont pour but de préciser le degré de lexicalisation des expressions données. Certains chercheurs nient tout de même l’utilité d’un critère particulier – surtout du critère sémantique, mais aussi du critère de lexicalisation (cf. W. Ucherek 2003 pour une revue de ces critères). C’est pourquoi, plus récemment, Stosic et Fagard (2019) ont proposé une méthode d’identification multicritère.
Bref, la fixation d’une limite nette entre les constructions syntaxiques libres et les locutions prépositives est souvent impossible ; on ne peut alors qu’indiquer approximativement le degré de locutionnalité d’une construction. Toutefois, indépendamment des hésitations théoriques, décider si une construction peut être considérée comme une locution prépositive est une nécessité pratique pour le lexicographe.
C’est justement les choix des lexicographes bilingues relatifs au traitement des locutions prépositives qui ont attiré notre attention. Dans la communication, qui s’inscrit dans le thème 9 du colloque, nous nous proposons d’examiner la place des locutions prépositives françaises dans les paratextes, les macrostructures et les microstructures de certains dictionnaires généraux français-polonais. Seront retenus les dictionnaires de grande taille et de taille moyenne, à savoir l’unique grand dictionnaire français-polonais (1980-1982), le Dictionnaire pratique français-polonais (1968), le Dictionnaire élémentaire français-polonais (1997) et le Dictionnaire Compact plus français-polonais (2001), et une sélection des dictionnaires de taille plus réduite, avant tout récents, comme par exemple le Dictionnaire Assimil Kernerman polonais-français, français-polonais (2009), le Dictionnaire universel français-polonais et polonais-français(2001), le Duży słownik polsko-francuski, francusko-polski Langenscheidt (2008), le Współczesny słownik francusko-polski, polsko-francuski Pons (2007) ou le Sprytny słownik francusko-polski i polsko-francuski (2010).
Une analyse préliminaire permet de constater que dans leurs énoncés introductifs, les dictionnaires consultés ne renseignent pas du tout sur le traitement lexicographique des locutions prépositives ; rappelons que parfois, il en est autrement par exemple dans le cas des locutions adverbiales. Or, si les prépositions élémentaires font normalement partie de la nomenclature du dictionnaire, celles appartenant à d’autres catégories des prépositions ne se laissent pas repérer aussi facilement. En effet, la présence des locutions prépositives dans la nomenclature n’est pas fréquente (cf. W. Ucherek 2019) ; si tel est le cas, ces locutions sont le plus souvent données dans l’ordre alphabétique de leur premier composant, mais aussi dans l’ordre de leur composant principal. En général, les locutions prépositives sont un peu plus susceptibles d’apparaître dans la nomenclature lorsque : elles s’ouvrent par une forme qui ne s’emploie pas en dehors de la locution ; il existe une locution adverbiale homonymique ; elles sont morphologiquement apparentées à une locution adverbiale ; elles sont considérées à tort comme des adverbes. Le plus souvent, les locutions prépositives sont à chercher dans des articles lexicographiques dédiés à leurs membres sémantiquement pleins. Apparemment, leur place dans la microstructure de ces articles peut être la suivante : elles figurent dans un sous-article ; elles figurent dans une rubrique à part ; elles figurent à la fin de l’article, dans une section entièrement consacrée aux expressions figées ; elles figurent à la fin d’une rubrique d’article, précédées d’un séparateur. Dans tous ces cas, nous nous intéresserons aux moyens utilisés par les lexicographes pour indiquer le statut prépositionnel (abréviations grammaticales telles que prép., prep., praep. ou przyim.) et/ou locutionnel (abréviations loc. ou expr., signes conventionnels comme un losange ou un triangle, italiques, …) de ces unités. Ensuite, nous porterons notre attention à des locutions prépositionnelles non identifiées comme telles, qui sont tout simplement citées parmi les exemples d’emploi du mot d’entrée, à l’égal des syntagmes libres.
L’analyse comparative des articles venant de plusieurs dictionnaires permettra tout d’abord de vérifier s’il existe un ensemble d’unités françaises généralement reconnues par les lexicographes bilingues comme locutions prépositives, mais aussi d’en dresser une liste maximale. La confrontation de la pratique lexicographique bilingue avec celle unilingue et avec des inventaires de prépositions figurant dans des travaux théoriques permettra de voir, premièrement, s’il y a des constructions dont le statut de locution prépositive ne soulève pas de doutes qui soient négligées par les lexicographes bilingues, et, deuxièmement, s’il y a des unités identifiées comme locutions prépositives dans les bilingues du corpus, mais pas dans les ouvrages de référence. Ensuite, l’examen du traitement microstructurel des prépositions complexes permettra d’évaluer la pratique lexicographique en la matière et, le cas échéant, de proposer quelques améliorations. Enfin, en élargissant un peu la perspective, nous essayerons de comparer l’inventaire des prépositions complexes françaises avec celui des prépositions polonaises, en nous appuyant notamment sur le dictionnaire des prépostions de Milewska (2003).
Ouvrages cités :
Borillo, A. (1997), Aide à l’identification des prépositions composées de temps et de lieu. Faits de Langues, 9, 175-184.
Delaunoy, A. (1967), Le bon emploi de la préposition en français. Namur, Wesmael-Charlier.
Gross, G. (1981), Les prépositions composées. In C. Schwarze (dir.), Analyse des prépositions. IIIe Colloque franco-allemand de linguistique théorique du 2 au 4 février 1981 à Constance. Tübingen, Max Niemeyer Verlag, 29-39.
Milewska, B. (2003), Słownik polskich przyimków wtórnych. Gdańsk, Wydawnictwo Uniwersytetu Gdańskiego.
Novikova, L.P. (1966), К вопросу о классификации предложных сочетаний в современном французском языке по степени их эквивалентности предлогу. In Проблемы лингвистического анализа. Москва, Издательство « Наука », 97-105.
Pougeoise, M. (1996), Dictionnaire didactique de la langue française. Paris, Armand Colin.
Stosic, D. & Fagard, B. (2019), Les prépositions complexes en français : pour une méthode d’identification multicritère. Revue Romane, 54 (1), 8-38.
Ucherek, E. (1997), Francusko-polski słownik przyimków. Warszawa, Wydawnictwo Naukowe PWN.
Ucherek, W. (2003), Problèmes de délimitation des prépositions composées. Romanica Wratislaviensia, L, 77-95.Ucherek, W. (2019), Les articles prépositionnels en lexicographie bilingue français-polonais. Paris, L’Harmattan.
Les prépositions complexes du domaine temporel : inventaire et description
Myriam Bras & Dejan Stosic
Nous nous intéresserons dans cette communication aux prépositions complexes temporelles (jusqu’à, à partir de, au cours de, lors de, à la fin de, au-delà de, au bout de, au début de, eu milieu de, au moment de, en fin de, tout au long, à l’occasion de, à la suite de, au fil de, au terme de, à l’issue de, il y a, à l’aube de, …). Nous partirons pour cela d’une liste de prépositions complexes (PrepComp) candidates, réunies sur la base d’une batterie de critères variés (cf. Borillo 1997, 2002, Adler 2001, Melis 2003, Fagard & De Mulder 2007, Stosic & Fagard 2019) et à partir de diverses sources lexicographiques, de grammaires et de la littérature sur le sujet (cf. notamment Borillo 1997, 2002, Melis 2003, Le Pesant 2006). L’ensemble des unités retenues se situent entre le lexique et la grammaire et établissent, à l’instar des prépositions simples, des relations fonctionnelles et sémantiques, en l’occurrence de type temporel, entre un élément recteur et un dépendant (cf. Melis 2003). Par leur nombre – une centaine, les prépositions complexes temporelles apparaissent en deuxième position, après les prépositions spatiales (cf. Stosic en préparation), ce qui confirme la place centrale du domaine temporel dans nos représentations linguistiques et conceptuelles.
Pour ce qui concerne le schéma de construction des PrepComp retenues, nous observerons la propension de la préposition à à être le formant initial de nombreuses prépositions complexes (à partir de, au cours de, à la fin de, au-delà de, au bout de, au début de, au moment de, à l’occasion de, à la suite de, au fil de, au terme de, à l’issue de, à l’aube de, …) dans une proportion qui représente plus de la moitié du corpus. Nous étudierons aussi la nature des éléments lexicaux qui les constituent et mettrons en évidence le lien entre ces éléments et le sémantisme des PrepComp formées. Trois domaines conceptuels semblent émerger pour les noms formant ces PrepComp : le temps (époque, période, instant, moment, temps, veille, lendemain, terme, date, début, fin …), l’espace (écart, issue, longueur, derrière, espace, voie, milieu…) et l’action (tombée, tombé, tomber, cours, départ, entrée, sortir, sortie, prolongement, attente, avance, coup…).
Nous définirons les PrepComp temporelles comme des prépositions permettant de construire des syntagmes prépositionnels jouant le rôle de complément de temps, au même titre que les prépositions temporelles simples à, dans, en, depuis, avant, après, pendant, pour, durant, sur, sous, vers, dès, jusque… Ces compléments, ou adverbiaux, temporels, ont été étudiés dans le détail ces dernières décennies. Nous nous appuierons en particulier sur les travaux toulousains initiés par Andrée Borillo (Borillo 1983, 1984, 1985, 1986, 1988, Molinès 1989, Bras et Molinès 1993, Aurnague et al. 2001) pour analyser le rôle des items prépositionnels complexes dans l’expression des relations temporelles.
Les prépositions simples se combinent avec deux types de syntagmes nominaux pour former des compléments de temps : des SN de durée (trois jours, un mois, des lustres…) ou des SN de localisation (mardi, Noël, l’été prochain, la veille, le 20ème siècle…), que nous nommerons SNdur et SNloc. Le SP construit peut à son tour exprimer la durée du procès (1, 2) ou localiser celui-ci (3, 4) ou indiquer à la fois la durée du procès et sa localisation temporelle (5) :
- Paul a fait le ménage de son appartement en deux heures.
- Marie s’est reposée à la campagne pendant un mois.
- Marie a téléphoné à Paul à midi / après le repas.
- Paul et Marie se sont revus après Noël.
- Marie est à la campagne depuis trois jours.
Un premier examen de la liste des PrepComp candidates au crible de ces deux distinctions montre qu’elles se combinent en grande majorité avec des SNloc et qu’aucun des SP qu’elles permettent de construire n’exprime la durée pure. Les SP obtenus font partie de la classe des adverbiaux de localisation temporelle (ALT), au sein de laquelle les PrepComp étudiées apportent des nuances non disponibles dans les ALT construits avec des prépositions simples comme la référence à des parties d’intervalles temporels (au début de l’hiver, en cours de semestre, au terme de …). Conformément au fonctionnement général des prépositions complexes, la présence d’un élément lexical dans leur structure entraîne une spécification sémantique plus grande (cf. Borillo 2002 : 144), ce qui, d’une part, réduit considérablement leur degré de polysémie et leur périmètre d’usage, et, d’autre part, augmente leur précision dans le marquage de relations sémantiques par rapport aux prépositions simples relevant du même champ sémantico-conceptuel.
Nous classerons également les SP selon le mode de calcul de la référence temporelle qu’ils induisent : s’agit-il d’un report de mesure temporelle (il y a deux mois) ou non (à la fin de l’hiver)? s’agit-il de la désignation d’une borne du référent temporel (à partir de demain, jusqu’à l’été prochain) ou non (au cours de la semaine prochaine, au milieu de l’été) ? Là aussi, les prépositions complexes se montrent plus aptes à exprimer des modes de calculs complexes que les prépositions simples, à l’exception de dans (dans trois jours) et depuis (depuis un mois, depuis Pâques).
Ce travail d’inventaire des formes et d’analyse de leur sens permettra d’enrichir la description de la catégorie des prépositions temporelles et de mieux comprendre l’articulation, au sein de la catégorie des prépositions, entre prépositions simples et prépositions complexes d’un même domaine sémantique.
Références bibliographiques
Adler, S. (2001). Les locutions prépositives : questions de méthodologie et de définition. Travaux de linguistique, 42-43,1, pp. 157-170.
Aurnague, M., Bras, M., Vieu, L., Asher, N. (2001), Syntax and Semantics of Locating Adverbials », Cahiers de Grammaire, 26, pp. 11-35.
Berthonneau, A.M. (1989). Composantes linguistiques de la référence temporelle. Les compléments de temps, du lexique à l’énoncé. Thèse d’Etat de l’Université Paris 7.
Berthonneau, A.M. (1991). Pendant et pour, variations sur la durée et donation de la référence. Langue française, 91, pp. 102-124.
Borillo, A. (1983). Les adverbes de référence temporelle dans la phrase et dans le texte. DRLAV, 29, 109-131.
Borillo, A. (1984). Pendant et la spécification temporelle de durée. Cahiers de Grammaire, 8, 57-75.
Borillo, A. (1985). Un congé de trois jours, trois jours de congé. Cahiers de Grammaire, 9, 3-20.
Borillo, A. (1986). Lexique et syntaxe : les emplois adverbiaux des noms de temps, In Actes du GRECO-CALF: Lexique et Traitement Automatique des Langues, Toulouse, Université Paul Sabatier, 11-23.
Borillo, A. (1988). L’expression de la durée : construction des noms et des verbes de mesure temporelle. Linguisticae Investigationes, 12/2, 363-396.
Borillo, A. (1997). Aide à l’identification des prépositions complexes de temps et de lieu. Faits de langue, 9, pp. 173-184.
Borillo, A. (2002). Il y a prépositions et prépositions. Travaux de Linguistique, 42-43, pp. 141-155.
Bras, M., Molinès, F. (1993). Adverbials of Temporal Location: linguistic description and automatic processing, in Darski J., Vetulani Z. (eds) Sprache—Kommunikation—Informatik, Akten des 26. Linguistischen Kolloquiums, Poznan 1991, Linguistische Arbeiten, 293, Max Niemeyer Verlag, Tübingen, pp. 137-146.
Fagard, B. & W. De Mulder (2007). La formation des prépositions complexes : grammaticalisation ou lexicalisation ? Langue française, 156, pp. 9-29.
Gross, M. (1986). Grammaire transformationnelle du français 3 : syntaxe de l’adverbe, Paris, Asstril.
Le Pesant, D. (2006), Classification à partir des propriétés syntaxiques. Modèles linguistiques, 53, pp. 51-74.
Melis, L. (2003). La préposition en français. Ophrys, Paris.
Molinès, F. (1989). Acceptabilité et interprétation des adverbiaux de localisation temporelle : grammaire ou dictionnaire. Mémoire de DEA, Université Toulouse 2.
Stosic, D. (en préparation). Les prépositions complexes en français.
Stosic, D. & Fagard, B. (2019), Les prépositions complexes en français : Pour une méthode d’identification multicritère, Revue romane, 54(1), pp. 8-38.
En / en l’espace de et l’expression de la durée en français
Ghayoung Kahng & Denis Vigier
Dans la présente communication, nous nous focaliserons sur le couple en / en l’espace de suivi d’un syntagme nominal exprimant (directement ou indirectement) une durée (= SNdur), tel qu’illustré sous (1)-(5). Les noms tête de ce type de SN peuvent être des noms de temps exprimant les « divisions habituelles du temps » (M. Gross, 1986 : 207) comme dans (1)-(3), ainsi que des noms non proprement temporels mais qui contextuellement ouvrent à une interprétation de durée (4)(5).[1]
- Mon satellite d’observation personnel faisait le tour de la terre en vingt-quatre heures. (Frantext, R. Debray, Loués soient nos seigneurs, 1996)
- Un beau jour, en essayant un appareil, il fut carbonisé dans le ciel en l’espace de quelques secondes. (Frantext, A. Vialatte, Les fruits du Congo, 1951).
- J’aurais voulu que mes cheveux tombent ou blanchissent en une nuit. (Ph. Forest, Toute la nuit, 1999)
- Les situations se font et se défont en l’espace d‘un éclair. (A. Blondin, Ma vie entre les lignes, 1982)
- L’intérêt d’Avengers Infinity War ne réside pas : […] dans ses sauts de puce entre 4 planètes différentes qui, même éloignés de plusieurs millions d’année lumière sont atteintes en l’espace d’un café expresso à la buvette. (<http://culturaddict.com/>, 18/12/2018)
Comme le montre A. Le Draoulec (2019), le nom espace, « éminemment spatial », peut recevoir en français contemporain une acception temporelle. Tel est le cas des emplois étudiés ici.
En lien avec le thème de ce colloque, nous chercherons en premier lieu à déterminer dans quelle mesure la séquence en l’espace de vérifie en français contemporain les traits morphologiques, syntaxiques et sémantiques généralement affectés aux prépositions complexes (PrepComp). En termes de typologie, cette séquence relève du schéma A3 : P1 le/la/les N P2 proposé par Melis (2003 : 107), ou, si l’on se tourne vers la liste établie par Stosic & Fagard (2019 : 15), de la structure à noyau nominal N1 : P Dét N P. Dans notre analyse, nous privilégierons l’approche fondée sur le concept de gradient de prototypicalité défendue par Stosic & Fagard (ibid.). Nous montrerons que si on applique à la séquence en l’espace de les tests à même de vérifier les vingt-et-un critères que proposent les auteurs (ibid: 21-22) dans leur « grille d’identification des prépositions complexes » (p. 21), cette séquence manifeste un comportement qui la situe nettement parmi les PrepComp pour sa matrice d’appartenance. Après avoir présenté notre mise en œuvre de cette grille, nous discuterons plus particulièrement quelques critères qui y sont mis en jeu à la lumière des études parues sur le sujet (e.a. Adler 2001, Borillo 1997, François & Manguin 2006, Gross 1996), en nous focalisant particulièrement sur les critères de « référentialité » et de « score d’information réciproque ».
Nous étudierons ensuite, en nous appuyant sur les bases textuelles Frantext[2] et BTLC[3], les concurrences d’emplois entre les syntagmes prépositionnels en SNdur et en l’espace de SNdur. On le sait, les PrepComp prototypiques en français apparaissent « comme équivalents fonctionnels des prépositions simples du point de vue distributionnel et sémantique » (Stosic & Fagard, ibid. :12). De fait, on observe qu’en français contemporain, la commutation de en et de en l’espace de devant un complément exprimant une durée est très souvent possible sans variation significative de sens, comme l’illustrent (1a)-(4a) en parallèle avec (1)-(4)
(1a) Mon satellite d’observation personnel faisait le tour de la terre en l’espace de vingt-quatre heures.
(2a) Un beau jour, en essayant un appareil, il fut carbonisé dans le ciel en quelques secondes.
(3a) J’aurais voulu que mes cheveux tombent ou blanchissent en l’espace d’une nuit.
(4a) Les situations se font et se défont en un éclair.
Nous montrerons ainsi que les compléments de durée construits avec la préposition simple (Vigier 2017a, pour une synthèse) ou avec son pendant complexe sont soumis aux mêmes contraintes distributionnelles dans le domaine de l’aspect lexical des verbes qu’ils modifient et des situations qu’ils concourent à construire (C. Vetters, 1996 : 96).
Nonobstant une indéniable parenté des restrictions sélectionnelles pesant sur l’emploi de ces deux prépositions, on observe que dans certains énoncés la commutation entre l’une et l’autre semble problématique comme dans (5a)(6a)(7a) :
(5a) L’intérêt d’Avengers Infinity War ne réside pas : […] dans ses sauts de puce entre 4 planètes différentes qui, même éloignés de plusieurs millions d’année lumière sont atteintes ??en un café expresso à la buvette.
(6) Ce qu’ils découvrent à Bakou, en l’espace de quelques journées dramatiques, c’est que les peuples dominés ou anciennement dominés (…) ne veulent plus être des instruments des bolcheviks. (Frantext, H. Carrère d’Encausse, L’Empire éclaté, 1978).
(6a) Ce qu’ils découvrent à Bakou, ??en quelques journées dramatiques, c’est que les peuples dominés ou anciennement dominés (…) ne veulent plus être des instruments des bolcheviks.
(7) Au surplus, la diminution de substance et, par conséquent, de puissance infligée à la France pendant les deux guerres mondiales n’a fait qu’accentuer l’abaissement qu’elle avait éprouvé en l’espace de deux vies humaines.(Ch. De Gaulle, Mémoires de guerre, 1959).
(7a) Au surplus, la diminution de substance et, par conséquent, de puissance infligée à la France pendant les deux guerres mondiales n’a fait qu’accentuer l’abaissement qu’elle avait éprouvé ???en deux vies humaines.
L’étude de ces contextes où la commutation entre la PrepComp et la préposition simple en devant SN de durée apparaît problématique, couplée à celle d’énoncés dans lesquels en l’espace de a été préféré à en qui eût néanmoins été possible, nous conduira à formuler des hypothèses relatives aux traits qui, dans l’identité sémantique de la PrepComp, contribuent à la différencier de sa concurrente simple en. Nous montrerons en outre que i) la moindre cohésion (E. Spang-Hansen, 1963) du SP formé avec cette PrepComp et (corrélativement) sa moindre abstraction, ii) le sémantisme du noyau lexical de la PrepComp dont A. Le Draoulec (2019 : 99-123) dit qu’il conserve toujours « une trace spatiale », conduisent à un profilage de la durée différent de celui qu’opère la préposition simple en. Enfin, pour nous aider à cerner les singularités propres à l’identité sémantique de en l’espace de par contraste avec en, nous nous appuierons sur les méthodes d’exploration probabiliste des cotextes d’apparition de ces deux prépositions en corpus (e.a. Blumenthal, 2008 ; Kraif, Tutin & Diwersy, 2014). Ainsi observe-t-on par ex. que dans les corpus de presse (BTLC) ainsi que dans Frantext, la PrepComp manifeste une attraction particulière pour les compléments de durée ayant pour tête le N génération, affinité absente des emplois de en. Une telle observation sera à mettre en relation avec nos autres analyses.
Dans une troisième et dernière partie, nous présenterons une étude diachronique des évolutions d’emplois de la séquence en l’espace de SNdur en recourant aux bases textuelles Frantext, BVH[4] et BFM[5]. Nous rappellerons d’abord que le motif préposition + l’espace de + SNdur a connu des réalisations variées dans l’histoire français. Nous nous intéresserons ensuite à l’apparition du SN l’espace de suivi d’un complément nominal de durée en français, attesté dans Frantext dès la première moitié du XIIIe s. et dont l’usage semble connaître une particulière embellie entre le XIVeet le XVIe s. Nous nous tournerons ensuite vers les séquences (en + dans) l’espace de SNdur. L’émergence de la seconde est évidemment liée à l’accroissement spectaculaire des usages de dans en français à partir de la deuxième moitié du XVIes (e.a. Gougenheim, 1945 ; de Mulder, 2008 ; Fagard & Sarda 2009). Nous chercherons à déterminer quelle incidence la reconfiguration de la sémantique de en, qu’on observe en français entre le XVIe s et le XVIIIe (e.a. Fagard & Combettes, 2013; Vigier 2017 b), du fait de l’entrée de dans sur la scène des prépositions les plus courantes du français, a eu sur l’interprétation des deux séquences en l’espace de SNdur et dans l’espace de SNdur.
Dans notre conclusion, nous élargirons notre comparaison des usages de en l’espace de SNdur avec ceux de la séquence en l’intervalle de SNdur
Bibliographie
Adler, S. (2001), « Les locutions prépositives : questions de méthodologie et de définition », Travaux de linguistique, 42-43,1, 157-170.
Berthonneau, A.-M. (1989), Composantes linguistiques de la référence temporelle. Les compléments de temps, du lexique à l’énoncé, Thèse de Doctorat d’État, Université Paris VII.
Blumenthal, P. (2008), « Combinatoire des prépositions. Approche quantitative », Langue Française, 157, 37-51.
Borillo, A. (1997), « Aide à l’identification des prépositions composées de temps et de lieu », Faits de langue, 9, 173-184.
De Mulder W. (2008), « En et dans : une question de « déplacement » ? », in O. Bertrand et al. (éds), Discours, diachronie, stylistique du français. Études en hommage à Bernard Combettes, Bern : Peter Lang, 277-291.
Fagard B. & Combettes B. (2013), « De en à dans, un simple remplacement ? Une étude diachronique », Langue Française 178, 95-119.
Fagard B. & Sarda L. (2009), « Etude diachronique de la préposition dans », in J. François, E. Gilbert, C. Guimier & M. Krause (éds..), Autour de la préposition: position, valeurs, statut et catégories apparentées à travers les langues,Bibliothèque de Syntaxe et Sémantique, Caen : PUC, 225-236.
François J, Manguin JL (2006), « Dispute théologique, discussion oiseuse et conversation téléphonique : les collocations adjectivo–nominales au cœur du débat », Langue Française, 150, 50-65
Gougenheim G. (1945, [1970]), « Les prépositions « en » et « dans » dans les premières œuvres de Ronsard », in Etudes de grammaire et de vocabulaire français, réunies sur l’initiative de ses collègues et amis pour son soixante-dixième anniversaire, Paris : Picard, 66-76.
Gross, G. (1996): Les expressions figées en français. Noms composés et autres locutions. Ophrys, Paris.
Gross, M. (1986), Grammaire transformationnelle du français. 3. Syntaxe de l’adverbe, Paris, Asstril.
Kraif, O., Tutin, A. & Diwersy, S. (2014), « Extraction de pivots complexes pour l’exploration de la combinatoire du lexique : une étude dans le champ des noms d’affect », Actes du 4e Congrès Mondial de Linguistique Française, Berlin, Allemagne, 19-23 Juillet 2014, volume 8.
Le Draoulec, A. (2019) « (L’)espace de » versus « (le) temps de », revue Scolia, n° 33, pp.99-123.
Martinie, B. & Vigier, D. (2013), « Le régime nominal de la préposition en dans la construction « être en + N abstrait » : une étude aspectuelle ». Langue française, 178 (2), pp.59-79.
Melis, L. (2003), La préposition en français, Paris : Ophrys.
Spang-Hansen, E. (1993), « De la structure des syntagmes à celle de l’espace. Essai sur les progrès réalisés dans l’étude des prépositions depuis une trentaine d’années », Langages 110, 12-26.
Stosic, D. & Fagard, B. (2019), « Les prépositions complexes en français. Pour une méthode d’identification multicritère », Revue romane, 54 (1), p. 8-38.
Vetters, C. (1996), Temps, Aspect et narration, Amsterdam-Atlanta, Edition Rodopi B.V.
Vigier, D. (2017a), « Autour des SP adverbiaux aspectuels en DétQuant Ntps », in Quand les formes prennent sens. Grammaire, prépositions, constructions, système, C. Vaguer (éd.), ed. Lambert-Lucas, p.113-123.
Vigier, D. (2017b), « La préposition dans au XVIe siècle. Apports d’une linguistique instrumentée », Langages, 206, 105-122.
[1] Par SNdur, nous entendons donc avec Le Draoulec (2019 : 100) les SN ayant pour tête, soit un NTemps (Gross, 1986), soit certains N abstraits pourvus d’une extension temporelle et dénotant une action, une activité, un état (v. Martinie & Vigier, 2013) soit encore « des noms plus divers, impliquant là encore indirectement une durée, comme café, jus, verre, cigarette ». Nous avons par ailleurs emprunté à cette auteure la notation SNdurainsi que notre exemple (5).
[2] https://www.frantext.fr/
[3] Développée par S. Diwersy à Montpellier 3.
[4] http://www.bvh.univ-tours.fr
[5] http://bfm.ens-lyon.fr