Marie Garnier
Doctorante allocataire, Monitrice, Université Toulouse – Jean Jaurès
mhl.garnier/@/gmail.com
Pour citer cet article : Garnier, Marie, « Les interactions au service de la correction d’erreurs. », Litter@ Incognita [En ligne], Toulouse : Université Toulouse Jean Jaurès, n°3 « Les Interactions II », 2010, mis en ligne en 2010, disponible sur <https://blogs.univ-tlse2.fr/littera-incognita-2/2018/01/09/la-ville-contemp…ite-au-generique/>.
Télécharger l’article au format PDF
Résumé
Dans cet exposé, nous utilisons l’observation en surface des relations d’enseignement/apprentissage naturelles afin de construire un correcteur grammatical innovant à vocation didactique, et s’adressant aux francophones souhaitant rédiger des textes en anglais. Ces situations naturelles étant riches en interactions, nous montrons comment elles peuvent être modélisées dans un système automatique, à l’aide, entre autres, des techniques de l’argumentation, de l’explication, et du profilage de l’utilisateur.
Mots-clés : anglais – grammaire – apprentissage – logiciel correcteur
Abstract
In this article, we use surface observations of natural teaching and learning situations that can be used in order to build an innovative grammar checker with a didactic dimension, and which is specifically targeted at French native speakers writing texts in English. Those natural situations are rich in interactions, and we show how these interactions can be implemented in an automatic system, using the techniques and technologies of argumentation, explanation, and user profiling.
Key-words: english language – grammar – learning – proofreading software
Sommaire
1. Projet CorrecTools
2. La relation d’enseignement/apprentissage
3. La création d’interactions entre système et utilisateur
4. Les interactions entre systèmes automatiques
Conclusion et perspectives
Bibliographie
Le projet collectif CorrecTools, mené par les laboratoires CAS et LLA de l’Université Toulouse – Jean Jaurès et l’IRIT de l’Université Toulouse III – Paul Sabatier, a pour point de départ une observation simple : les textes rédigés en anglais par des francophones contiennent souvent des erreurs grammaticales, lexicales et stylistiques, et ceci en dépit de l’offre conséquente des correcteurs grammaticaux existant en ligne ou sous forme de logiciels. En effet, de nombreuses erreurs grammaticales ou stylistiques complexes ne sont pas à cette heure prises en charge par ces systèmes. L’un des objectifs du projet CorrecTools est de mettre en place un système de correction innovant, offrant une aide à la rédaction en deux volets : correction des erreurs d’une part, et d’autre part amélioration des compétences de l’utilisateur par le biais de différentes techniques (i.e. explication, argumentation, question-réponse). Le projet incluant une composante didactique, il est nécessaire d’observer et de modéliser des situations d’enseignement et d’apprentissage « naturelles ». L’observation des interactions existant dans ces relations, et leur imitation dans un système automatique, peut en améliorer l’efficacité. Dans cette communication, nous commençons par une présentation plus détaillée du projet CorrecTools, puis nous nous intéressons aux interactions découlant d’une relation d’enseignement/apprentissage « naturelle », avant d’explorer les modalités de leur mise en place dans un système automatique. Finalement nous évoquerons brièvement les possibilités d’interaction entre différents systèmes et ressources automatisés.
1. Projet CorrecTools
1.1. Les erreurs produites par les francophones s’exprimant en anglais
L’une des particularités du projet CorrecTools réside dans le choix de s’adresser à un public de francophones, et donc de prendre en compte dans le corpus d’exploration uniquement des textes rédigés en anglais par des locuteurs natifs du français. Ce choix est sous-tendu par l’observation de l’importance du transfert syntaxique dans l’apprentissage et l’utilisation d’une langue seconde. L’expression « transfert syntaxique » est utilisée lorsqu’un locuteur (ou rédacteur, dans notre contexte) utilise les structures ou les règles de sa langue maternelle pour produire des énoncés dans une langue seconde. Cette tendance, qui relève de l’analogie, est largement observée dans le processus d’apprentissage (Ellis, 1994), et peut également s’appliquer à d’autres aspects de la langue, tels que le lexique. Dans le domaine de la traductologie et de l’enseignement de la traduction, ce phénomène est souvent appelé « calque ». Sa prise en compte présente de nombreux avantages pour la correction des erreurs, qu’elle soit automatique ou humaine, car elle permet d’identifier plus précisément les causes d’une erreur et d’employer des moyens plus directs pour y remédier. Considérons la phrase « Are you agree? » relevée dans notre corpus. Un correcteur humain anglophone ne maîtrisant pas le français pourra diagnostiquer cette erreur comme découlant d’un manque de connaissance des caractéristiques de agree, qui est un verbe et ne peut donc pas être utilisé sous sa forme non conjuguée avec une fonction d’attribut du sujet, comme c’est le cas dans notre exemple. Cette analyse est tout à fait correcte, et il est sans doute utile d’expliquer l’erreur en ces termes à la personne ayant produit ce segment. Toutefois, l’erreur a également une cause qui nous semble plus évidente : il s’agit d’une imitation de la construction française avec la locution verbale être d’accord, qui donnerait « Êtes-vous d’accord ? » Une explication de l’erreur qui soulignerait les différences entre les constructions idiomatiques française et anglaise pourrait d’une part être mieux comprise et assimilée par un apprenant/utilisateur ayant peu de connaissances en grammaire, et d’autre part attirer l’attention sur le phénomène du transfert syntaxique afin d’amorcer une prise de conscience de l’utilisateur de ses propres stratégies, ce qui pourrait permettre d’éviter la reproduction de ce type d’erreur.
Prendre en compte ce phénomène dans la construction d’un correcteur automatique a également pour conséquence de limiter les publics pouvant utiliser ce système. Pour cette raison, nous nous efforçons, dans le cadre du projet CorrecTools, d’explorer d’autres paires de langues (espagnol vers anglais, français vers espagnol), ainsi que de rendre le système transférable à d’autres langues.
De nombreux types d’erreurs courantes sont déjà traités par les correcteurs automatiques les plus utilisés, tels Cordial (Systran, intégré à Microsoft Word 2007), WhiteSmoke ou Grammatica. Les erreurs d’orthographe, de typographie et de morphologie simple (accord en genre et en nombre, conjugaison, certaines erreurs de composition des temps), ainsi que, dans certains cas, les erreurs de syntaxe simple (phrases sans verbe), ne représentent plus un défi pour la correction grammaticale automatique. Cependant, les systèmes existants restent muets devant des erreurs grammaticales complexes, liées à des règles ou principes difficiles à maîtriser (ex : utilisation des articles, placement des adverbes, choix des prépositions, etc.). Ce sont donc ces erreurs auxquelles nous tenterons d’apporter une correction automatique dans le cadre du projet CorrecTools. Afin de construire un système aussi pertinent que possible, les types d’erreurs qui seront corrigés feront partie des erreurs représentatives chez les locuteurs francophones, et donc fréquentes dans leurs productions.
1.2. Un corpus construit pour une approche généraliste
Dans une visée démocratique, le système de correction final doit pouvoir s’adresser à tous types de publics et apporter ainsi une aide à des groupes d’utilisateurs très différents, dans la réalisation de tâches variées et courantes, telles que la rédaction d’e-mails personnels ou professionnels, de notes de blogs, de rapports, de publications, etc. Les utilisateurs de ce système devront cependant présenter un niveau de compétence en anglais allant de moyen à avancé. En effet, les apprenants débutants ou les utilisateurs ayant un niveau de compétence faible ont des besoins très différents des utilisateurs avancés, et ne pourraient profiter d’un système proposant des corrections de segments déjà complexes.
Le corpus que nous avons constitué illustre ce choix généraliste (Albert et al., 2009). Il comprend des publications scientifiques, des rapports d’entreprises, des sites internet professionnels, des e-mails professionnels, semi-professionnels et personnels, ainsi que des productions d’apprenants issues du International Corpus of Learner English constitué à l’Université Catholique de Louvain (Granger et al., 2009). Ce corpus exploratoire comprend donc des productions d’apprenants de l’anglais, c’est-à-dire de personnes s’inscrivant dans une démarche d’apprentissage dont le but principal n’est pas forcément l’utilisation de la langue dans des situations réelles, ainsi que d’utilisateurs de l’anglais, qui se servent de la langue plus ou moins régulièrement afin de communiquer, sans pour autant demeurer dans une démarche d’apprentissage (Cook et al., 2002). Il est important de souligner cette distinction, et sa prise en compte dans la constitution du corpus, car elle aura des répercussions sur la présentation des corrections (explications plus ou moins étoffées selon l’utilisateur, corrections simples sans explications, etc.).
2. La relation d’enseignement/apprentissage
Le choix de l’expression « enseignement/apprentissage » n’est pas anodin : la conjonction de ces deux mots est utilisée en didactique afin d’illustrer le fait que si les apprenants reçoivent un enseignement de la part d’une autre personne, ils ne sont pas pour autant de simples bénéficiaires passifs, mais sont au contraire pleinement actifs et responsables de leur apprentissage. Cette relation n’est pas « descendante » mais doit fonctionner dans les deux sens, de l’enseignant vers l’apprenant, et de l’apprenant vers l’enseignant. Les interactions y ont par conséquent une place importante.
Nous avons identifié plusieurs types larges d’interactions possibles lors d’un enseignement de langue. Il ne s’agit pas ici de rentrer dans le détail des relations complexes qui se nouent lors d’un processus d’enseignement/apprentissage, mais de les ébaucher à larges traits, afin d’identifier les situations naturelles pouvant être reproduites lorsque la correction est automatique. La modélisation des réponses fournies par les enseignants/apprenants à ces situations est ensuite utilisée dans le but d’améliorer l’efficacité et l’ergonomie du système. Tout d’abord, l’apprenant peut simplement interroger l’enseignant. L’enseignant peut proposer plusieurs réponses, expliquant éventuellement leurs différentes caractéristiques, ainsi que leurs avantages et inconvénients. Ceci fournit des informations à l’apprenant, qui peut alors faire un choix. On retrouve le même type d’interaction dans le cas d’une demande de correction. Nous avons également identifié un autre cas de figure dans lequel l’enseignant sollicite l’apprenant afin qu’il lui fournisse un complément d’information car il ne peut répondre à sa question ou proposer une correction sans cette information. Il existe aussi des interactions ayant lieu en amont de l’enseignement, lorsque l’apprenant communique des informations à l’enseignant afin que ce dernier puisse s’adapter aux besoins et aux caractéristiques de son public. Dans un cours de langue, ces informations pourront porter sur la langue maternelle de l’apprenant, son niveau de compétence, ses besoins spécifiques, son âge, etc.
À ces situations « naturelles » correspondent des situations de correction automatique. Lorsque plusieurs corrections sont possibles et ne sont pas parfaitement équivalentes, l’utilisateur peut avoir besoin d’indications complémentaires afin de pouvoir faire un choix adapté. Dans certains cas, par exemple lorsque la correction implique l’insertion d’un pronom ou groupe nominal qui n’est pas présent dans le segment original, un système automatique devra interroger l’utilisateur afin d’obtenir les informations nécessaires à une correction satisfaisante. Enfin, un système automatique peut utiliser des informations données en amont par l’utilisateur (besoins, type de document, etc.) pour adapter ses corrections et la quantité des explications qui l’accompagnent. Dans les paragraphes suivants, nous allons illustrer ces situations par des exemples, et nous montrerons en quoi un défaut de prise en compte de ces interactions nécessaires peut conduire à un échec des corrections.
3. La création d’interactions entre système et utilisateur
3.1. Quelques exemples d’échecs de corrections dans MS Word 2007
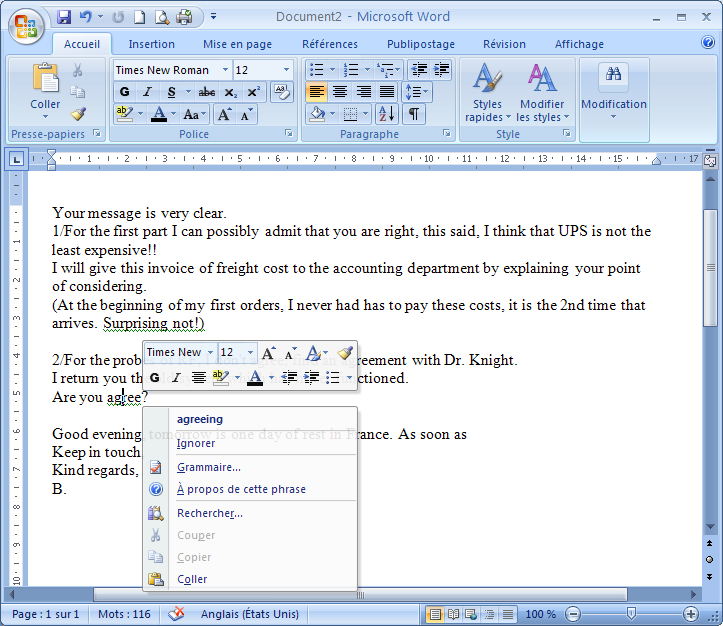
Reprenons l’exemple de segment erroné que nous avons cité plus haut : « Are you agree? » Ce segment bénéficie d’une proposition de correction dans Word 2007, visible sur la capture d’écran suivante :
Capture d’écran 1
Le correcteur intégré propose de remplacer agree par agreeing, ce qui donnerait le segment Are you agreeing? Cette proposition rétablit la grammaticalité du segment, mais est peu idiomatique et ne pourrait être énoncée ou écrite naturellement par un anglophone natif que dans un contexte très particulier. Il semblerait que le correcteur automatique ait noté l’utilisation agrammaticale du verbe et ait proposé la correction la plus proche, c’est-à-dire un changement de la base verbale simple en forme en –ING, qui forme l’aspect progressif avec l’auxiliaire BE. Cette méthode ne prend pas en compte le phénomène de transfert syntaxique que nous avons décrit plus haut. Ce manque d’informations en amont sur l’utilisateur et sa langue maternelle conduit à une correction certes grammaticale, mais qui n’évite pas l’écueil du manque d’authenticité. De plus, une telle correction sans explication ne permet pas à l’utilisateur d’éviter que cette erreur soit reproduite, et peut également lui faire accepter comme correcte une expression non-idiomatique.
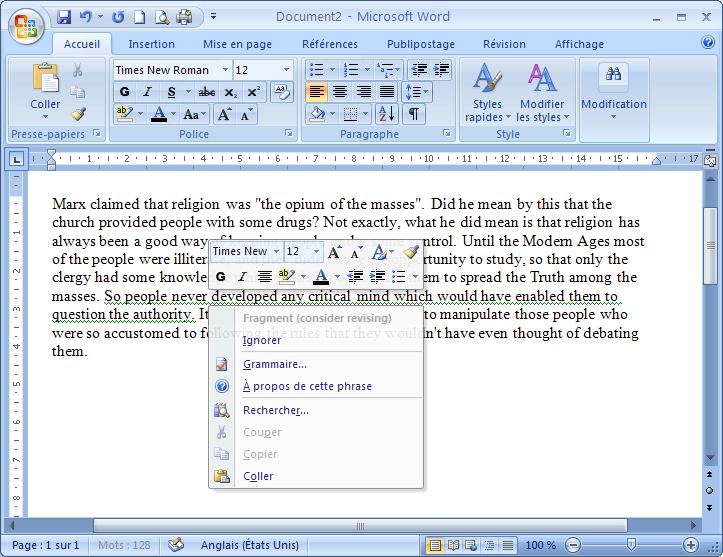
Prenons l’exemple du segment suivant tiré de notre corpus : So people never developed any critical mind […] to question the authority. En voici le traitement par le correcteur de Word :
Capture d’écran 2
Il s’agit ici plutôt d’une erreur de style, puisque la phrase commence par une conjonction qui ne doit pas, selon les grammaires prescriptives, se trouver en position initiale dans une phrase. Le correcteur de Word détecte donc un fragment et conseille à l’utilisateur de réviser son segment (« consider revising »). Cependant, laissé sans aucune indication quant à la cause de l’erreur, c’est-à-dire ce qui rend la phrase incorrecte, ou d’informations concernant son degré d’incorrection (en effet, il est seulement conseillé de réviser le segment), l’utilisateur ne dispose pas des informations nécessaires pour rectifier lui/elle-même sa production.
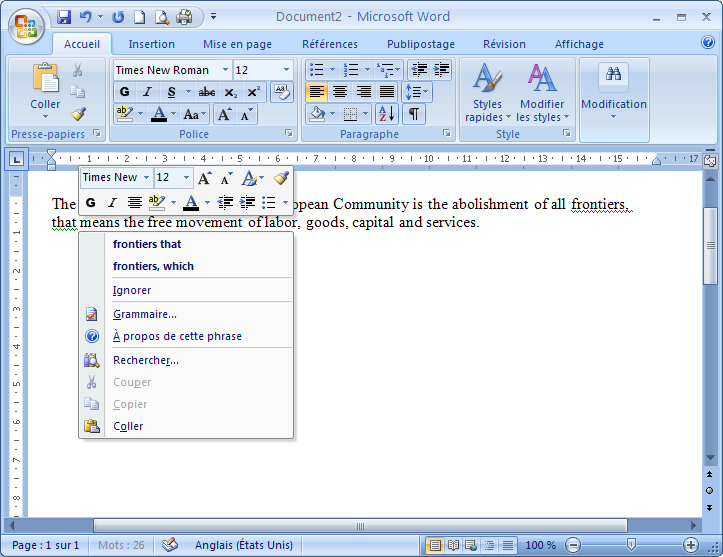
Prenons un dernier exemple : The goal […] is the abolishment of all frontiers, that means the free movement of labor […]
Capture d’écran 3
Ici l’erreur porte sur la nature de la proposition relative, qui peut être restrictive (frontiers that) ou non-restrictive (frontiers, which). Cependant, même si le correcteur fait apparaître ces deux possibilités, elles ne sont accompagnées d’aucune information quant aux différentes interprétations du message selon le type de proposition relative, et l’utilisateur ne peut faire qu’un choix à l’aveugle (ou en se fondant sur ses propres connaissances de la langue), sans en connaître les conséquences syntaxiques et sémantiques.
Les trois exemples rassemblés ici constituent une première indication des avancées en terme d’efficacité et de pertinence pour l’utilisateur, que pourrait permettre la prise en compte des interactions qui existent nécessairement dans une relation d’enseignement/apprentissage.
3.2. Méthodes et théories à mobiliser
L’inclusion d’interactions système/utilisateur dans un correcteur automatique implique l’utilisation de techniques et d’outils théoriques avancés, que nous détaillons dans les paragraphes suivants.
Une théorie de l’argumentation (Walton et al., 2008) peut être utilisée dans le cas de corrections concurrentes. Les annotations des erreurs sont mises à profit afin de faire ressortir les arguments pour et contre une correction particulière, leur attribuer un poids et une pertinence. Ceci peut être présenté sous la forme d’un paragraphe rédigé dans une langue compréhensible et attrayante pour l’utilisateur. Un théorie de la décision est également nécessaire pour proposer un choix prenant en compte les avantage et les inconvénients de chaque correction, et intégrant également les préférences de l’utilisateur (ex : priorité de l’intelligibilité vs priorité de la correction grammaticale). Voir (Garnier et al., 2009) pour une présentation détaillée des schémas d’annotation et des techniques utilisées pour la rédaction des paragraphes argumentatifs.
Nous avons vu que dans de nombreux cas, l’absence d’explication des erreurs peut empêcher l’utilisateur de tirer profit de la proposition d’une correction. Il semble donc nécessaire de générer des explications pour accompagner les corrections. Ceci peut être mis en place à l’aide de travaux sur les marques de l’explication (Bourse et al., 2009) en cours de réalisation, conjointement au projet CorrecTools. La mise en place d’explications pertinentes nécessite d’une part un questionnement sur la manière la plus ergonomique de présenter ces explications, qui peut être fondé sur des recherches en didactique des langues, et d’autre part d’évaluer l’importance relative des traditionnelles « règles de grammaire » et autres principes qui régissent la rédaction de phrases ou de textes plus longs (choix du focus, pragmatique, style, etc.).
Nous avons évoqué le cas de segments erronés ne pouvant être corrigés de manière satisfaisante qu’avec une implication de l’utilisateur dans la correction. C’est le cas pour le segment suivant : I am sorry, but he didn’t use. Le verbe use appelle un objet direct, et son absence rend la phrase agrammaticale et éventuellement difficile à comprendre, selon le contexte. Cependant, il est impossible de choisir arbitrairement le groupe nominal ou pronom qui doit être l’objet du verbe (He didn’t use it? He didn’t use them? He didn’t use the books?). Dans cette situation, un correcteur automatique doit avoir la possibilité d’indiquer à l’utilisateur la nature de l’erreur et le groupe syntaxique qui doit être ajouté, et de le laisser compléter la correction, avant de vérifier de nouveau la grammaticalité du segment.
Un autre moyen d’interagir avec l’utilisateur afin d’améliorer les corrections consiste à effectuer un suivi automatique des productions. Conserver un historique des erreurs produites et corrigées permet d’évaluer l’efficacité des explications : ainsi, une erreur corrigée une fois et reproduite peut indiquer que l’explication n’a pas été bien comprise, et doit donc être reformulée. On peut aussi utiliser ce suivi pour effectuer de meilleurs diagnostics d’erreurs, dans le cas des erreurs ayant plusieurs causes et plusieurs explications possibles.
Enfin, le profilage de l’utilisateur est encore un moyen de créer des interactions utiles. Un système de correction automatique devrait pouvoir répondre à des besoins différents selon la tâche effectuée, les compétences de l’utilisateur et le degré de correction/explication désiré. Par exemple, pour la rédaction d’un e-mail personnel, l’intelligibilité sera privilégiée au détriment de la grammaticalité ou du style, alors que ces deux derniers paramètres sont importants pour la rédaction de publications scientifiques. De plus, un utilisateur souhaitant rédiger un e-mail rapide pourra choisir de ne pas visualiser les explications et les textes argumentatifs, s’en remettant aux choix du système dans le cas de corrections concurrentes. La connaissance de la langue maternelle de l’utilisateur, un des principes du projet CorrecTools, peut également être considéré comme faisant partie d’un processus de profilage de l’utilisateur.
4. Les interactions entre systèmes automatiques
Dans une situation d’enseignement/apprentissage « naturelle », il arrive souvent que l’enseignant ait recours à des ressources extérieures afin de répondre de manière satisfaisante à une question, ou d’apporter un complément d’information à une correction. Ceci peut être mis en place dans un correcteur automatique. Le système peut par exemple faire appel à des ressources lexicales et grammaticales présentes en ligne ou intégrées au correcteur.
En cas d’incertitude face à des corrections multiples, le système peut également accéder à des moteurs de recherche afin de vérifier la fréquence des occurrences des différentes possibilités, leur contexte d’utilisation, etc. (un concordancier intégré peut également être utilisé pour cette tâche). Ceci a déjà été mis en place dans le Microsoft English Second Language Assistant, accessible en ligne et s’adressant plus précisément aux locuteurs de langues asiatiques (Leacock et al., 2009). Cet « assistant » utilise systématiquement le web afin d’évaluer la fréquence des occurrences des différentes possibilités de correction, et les présente à l’utilisateur sous forme de graphiques. Cependant, étant donné le pourcentage important de locuteurs en anglais de langue seconde qui publient sur internet, cette fonctionnalité doit être utilisée avec précaution.
Conclusion et perspectives
Dans cet exposé, nous avons tenté de montrer l’intérêt de l’observation des situations naturelles d’enseignement/apprentissage dans la construction d’un correcteur automatique à vocation didactique. Une analyse de surface révèle l’existence d’interactions importantes entre les différents acteurs de la relation d’enseignement/apprentissage. Ne pas les prendre en compte dans un système automatique peut mener à l’échec des corrections proposées. De plus ces observations permettent d’imaginer et de mettre en place des relations utilisateurs/machines innovantes et riches en perspectives. L’une des prochaines étapes du projet consiste en la tentative de mise en application des méthodes présentées, ainsi que des stratégies de correction auxquelles nous travaillons en parallèle, dans le cas des erreurs liées au placement de l’adverbe dans les groupes verbaux et les propositions.
Bibliographie
Albert C., Garnier M., Rykner A. et Saint-Dizier P. « Analyzing a corpus of documents written in English by native speakers of French: classifying and annotating lexical and grammatical errors ». Proceedings of the Corpus Linguistics Conference, 2009.
Bourse S., Fontan L., et Saint-Dizier P. « Analyzing argumentative and explicative structure markers in procedural texts ». Actes de la conférence LPTS, Paris, 2009.
Cook V. (ed.). Portraits of the L2 User. New York : Multilingual Matters, 2002, 360p.
Ellis R. The study of second language acquisition. Oxford : Oxford University Press, 1994, 824p.
Garnier M., Rykner A. et Saint-Dizier P. « Correcting errors using the framework of argumentation: towards generating argumentative correction propositions from error annotation schemas ». Proceedings of PACLIC, Hong-Kong, 2009.
Granger S., Dagneaux E., Meunier F. et Paquot M. (eds). International Corpus of Learner English v.2. Louvain La Neuve : Presses Universitaires de Louvain, 2009.
Leacock C., Gamon M., et Brockett C. « User Input and Interactions on Microsoft Research ESL Assistant ». Proceedings of the ACL-SIGPARSE conference, 2009.
Walton D., Reed C., et Macagno F. Argumentation Schemes. Cambridge : Cambridge University Press, 2008, 456p.
Laisser un commentaire